
how to swiftly take over Power Query with the help of some useful gear.

This blog article can be seen as a complement to the post how to crack the mystery of the mighty DAX. Having the same setup, it shall act as a cheat sheet for logic and code written in Power Query’s M. As a heads up, this post does not intend to cover every function nor shall it be anywhere close to a full documentation. Instead, it provides information, explanations and examples based on issues I have encountered myself either in my daily work or in community forums like community.powerbi.com or stackoverflow.com. This blog post is updated constantly. In case you are in need for some proper sample data to query from, have a look into how to add adventureworks sample to azure sql database.
Please note, many times you can solve an issue in either DAX or Power Query. While every use case is different and has its own requirements and pitfalls, generally you should consider Roche’s Maxim of Data Transformation. Sloppily speaking, if you have the choice between doing a calculation in Power Query or DAX, use Power Query! Also, in order to dig more deeply into the examples below, you can paste the M code “as is” into the advanced editor of a blank query. This is because we are not referencing to any external source or files.
.
table of content.
1. Unfold / expand / create rows between two dates
2. Get today’s or yesterday’s date
3. Create ranks and indexes
4. Check if values of one column exist in another column
5. Return table: one row of latest version / status per group
6. Return certain values from string
7. Replace values in column
8. Split by multiple delimiters
9. Calculate difference between rows
10. Create comma separated list per group
11. Calculate duration from “time” column
.
1. Unfold / expand / create rows between two dates
Very often you have a start and end date column which makes it hard to retrieve a state at a specific date (i.e. how many items were in state x on date y). This will be a lot easier if you change the grain of the table to “per day”.
Example:

.
Instead of having a start and end date we’d like to unfold all rows between the dates for each item in Column so we end up with this:
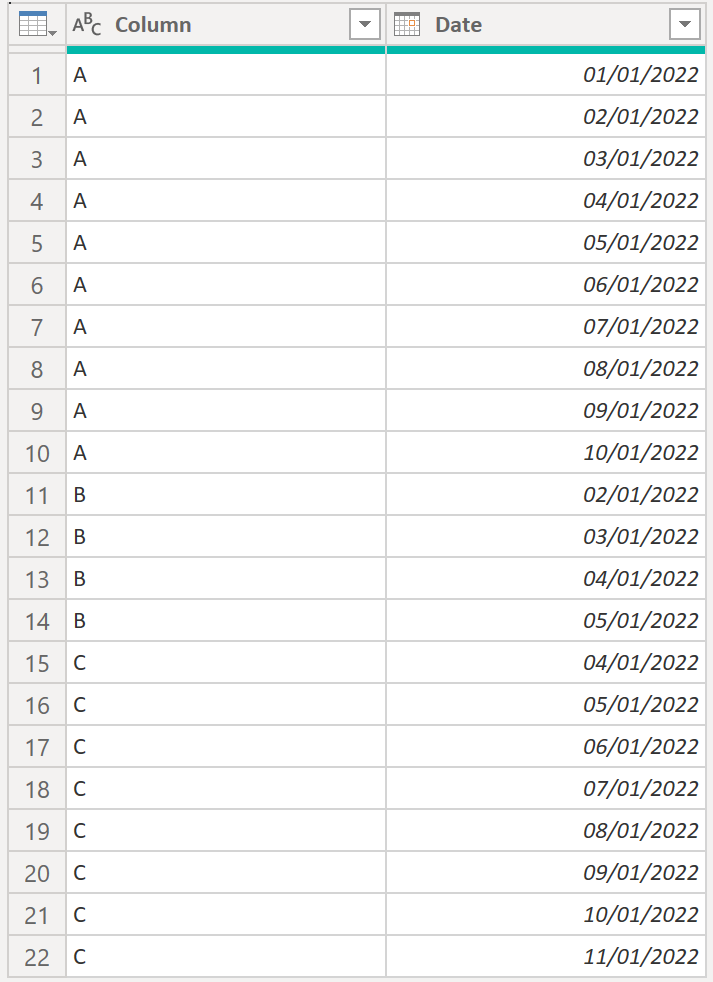
.
For this, we start off with our table having the two date columns in date format. Create a custom column like below:
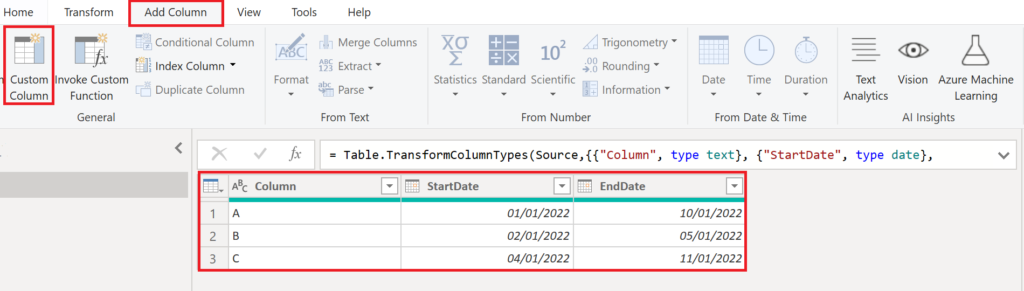
.
Name the column Date and paste the following code into the formula field:
{ Number.From ( [StartDate] ) ..Number.From ( [EndDate] ) }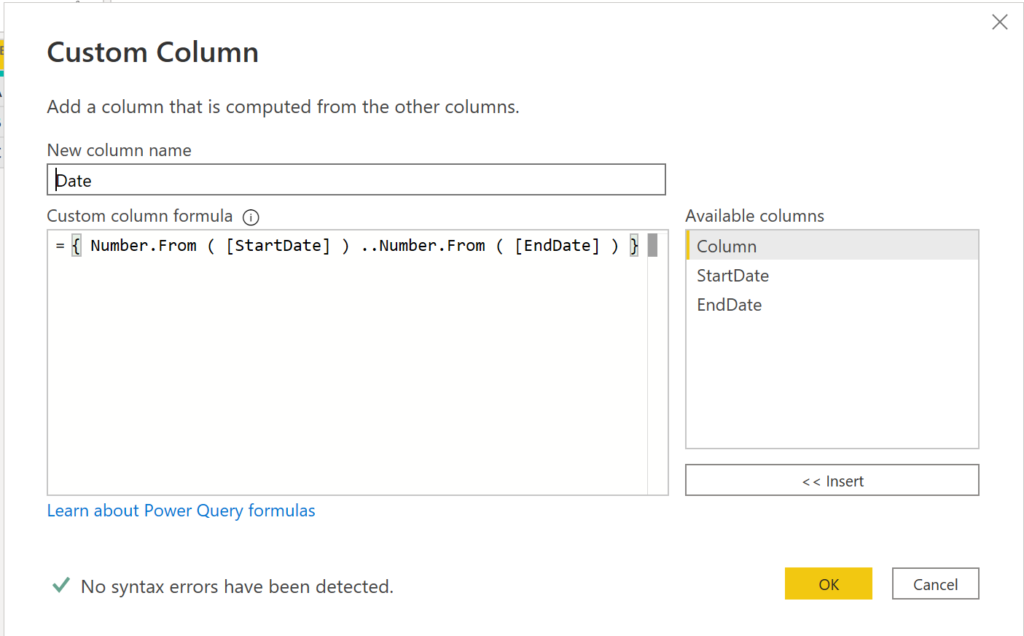
.
You should then end up with the new date column that just contains List values.

.
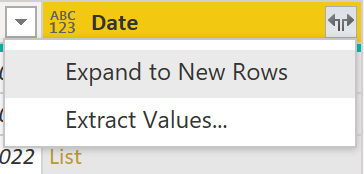
Click on the two arrows on the top right to expand the list:
.
You’ll probably end up with just integers not looking like a date at all. Don’t worry there are dates, just in the wrong format.

.
To fix this, select the column and change the format manually to date:
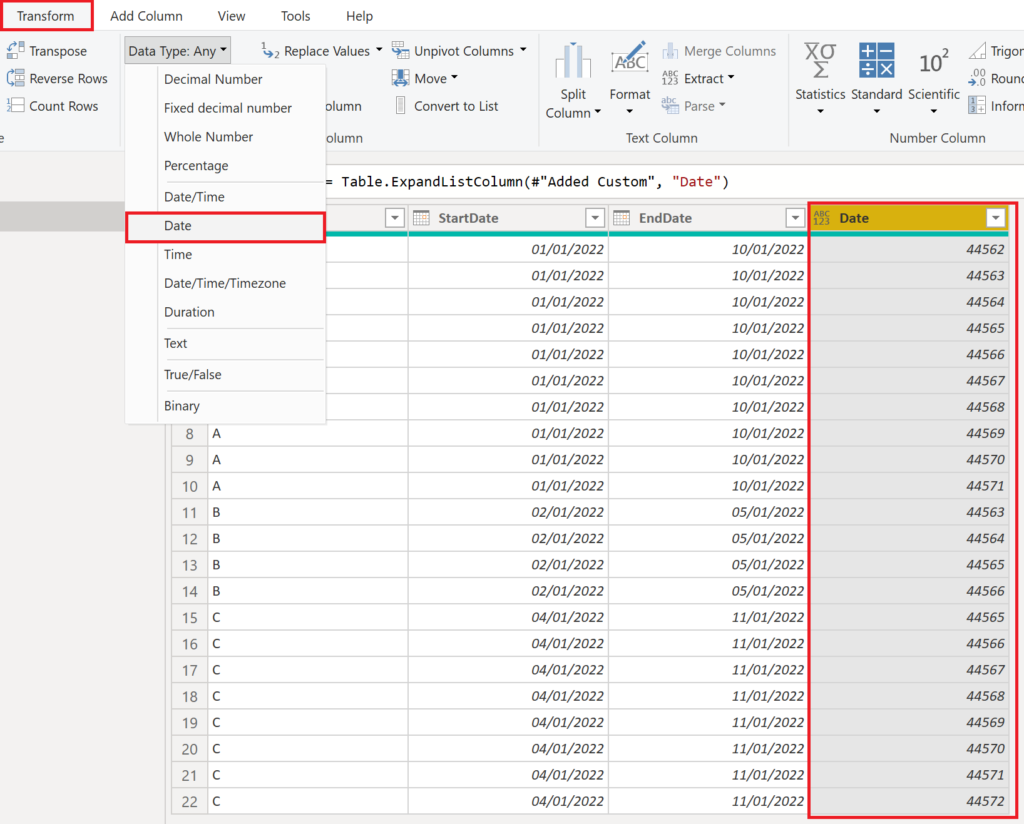
.
And here we are, we successfully changed the granularity to one row per date:
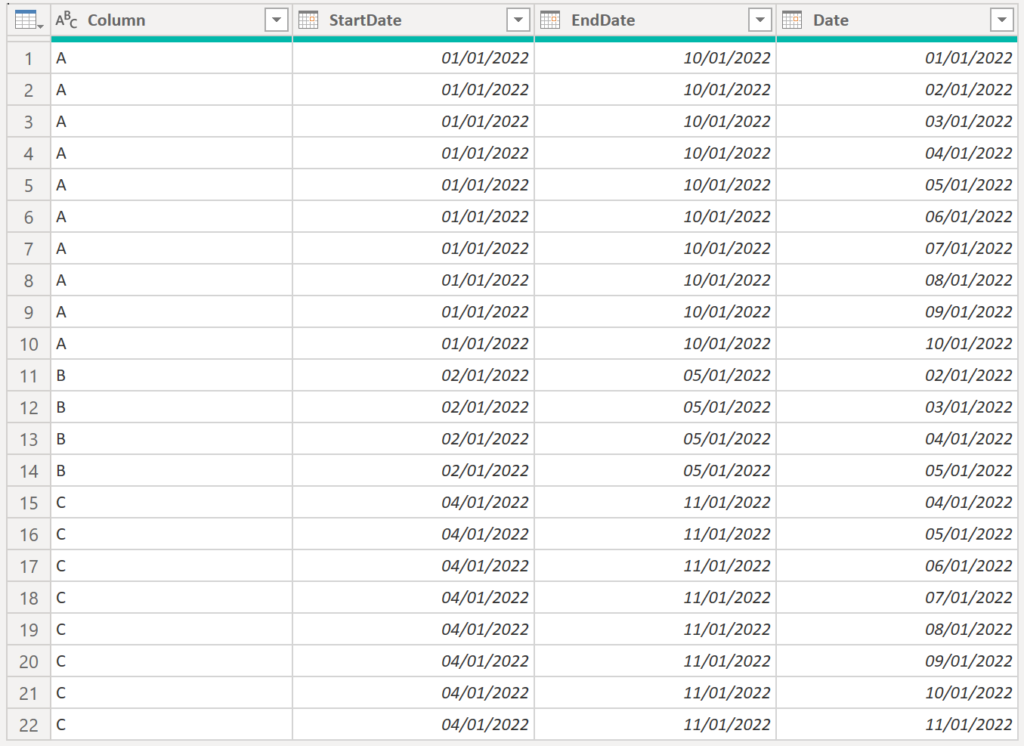
If you do not need the start and end date anymore, you can remove them by selecting, right clicking and pressing remove columns.
Here the code in advanced editor:
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45WclTSUTIyMDLSNTAEIiSOoYFSrE60khOyvBEyxxQs74wsZIKs31ApNhYA", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [Column = _t, StartDate = _t, EndDate = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"Column", type text}, {"StartDate", type date}, {"EndDate", type date}}),
#"Added Custom" = Table.AddColumn(#"Changed Type", "Date", each { Number.From ( [StartDate] ) ..Number.From ( [EndDate] ) }),
#"Expanded Custom" = Table.ExpandListColumn(#"Added Custom", "Date"),
#"Changed Type1" = Table.TransformColumnTypes(#"Expanded Custom",{{"Date", type date}})
in
#"Changed Type1".
2. Get today’s or yesterday’s date
Since there is no TODAY() function in Power Query as opposed to DAX, here a short code snippet to retrieve the date for today and yesterday:
Date.From(DateTime.LocalNow())Date.AddDays(Date.From(DateTime.LocalNow()), - 1).
Result:

.
You could use the dates as above, but it is more likely that you wanna do comparison with them.
.
3. Create ranks and indexes
Rank- and index columns are useful not only for introducing a natural and “easy way to manage” ordering but also as a pre-step for many other use cases. We have done the exact same thing with the exact same outcome in DAX, but most of the time it is recommended to create such indexes already in Power Query.
Example:
We have 6 students that all took exams in Biology, Mathematics and English with the following grades:
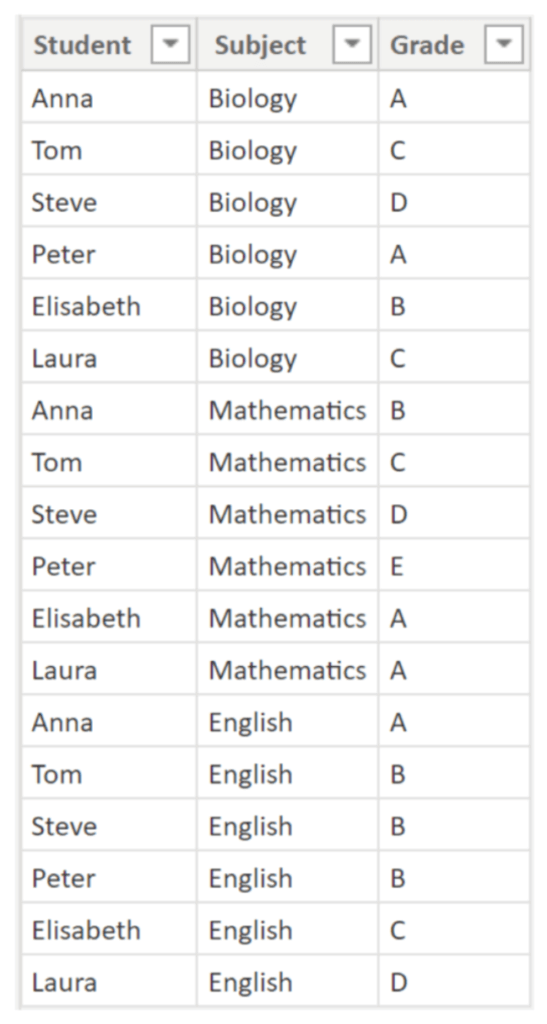
.
The goal is to create a grade ranking per subject or more generically a rank / index per group. To start off, we sort our table on the column which shall be used to create the index on:
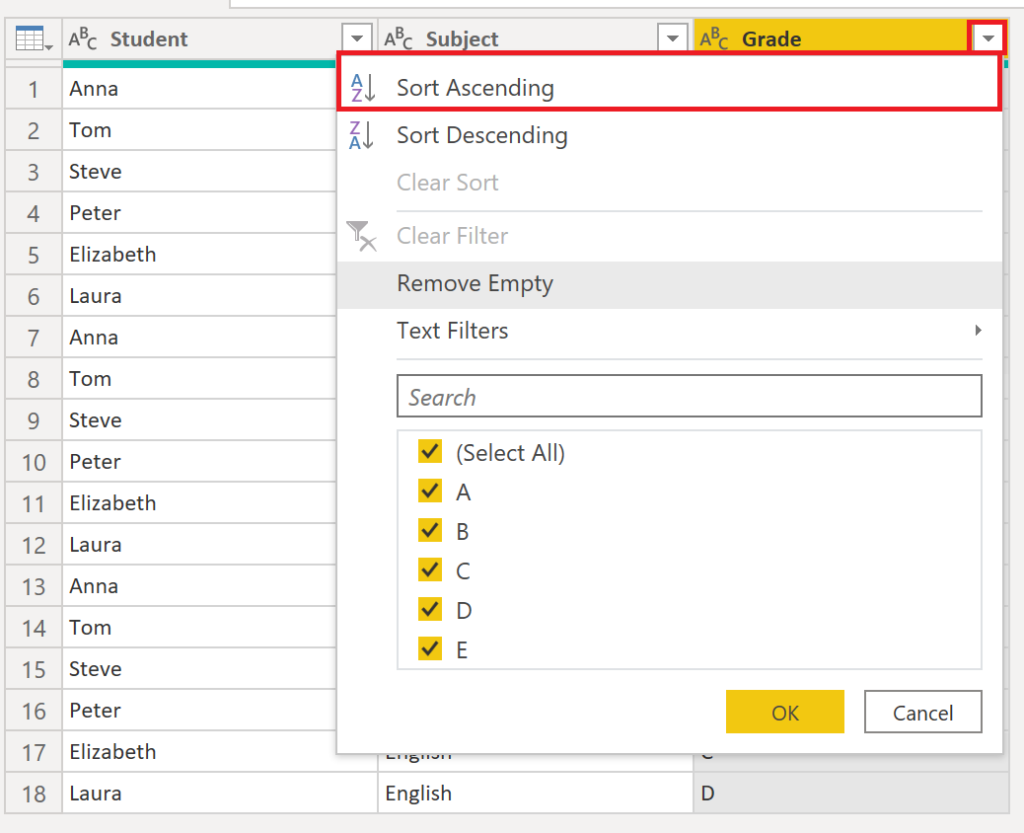
.
Next, right-click on the grouping column which in our case is the subject. Then choose Group By:
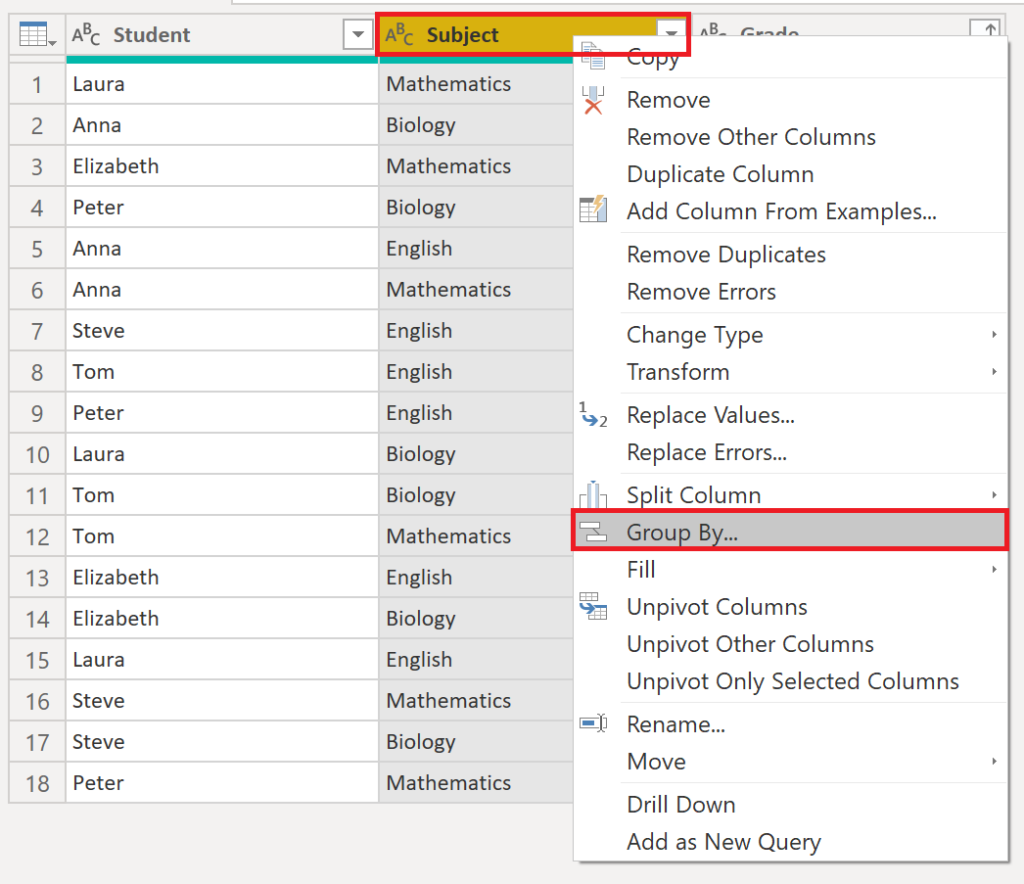
.
Fill in the Group By box accordingly, Make sure to select All Rows in the Operation dropdown:
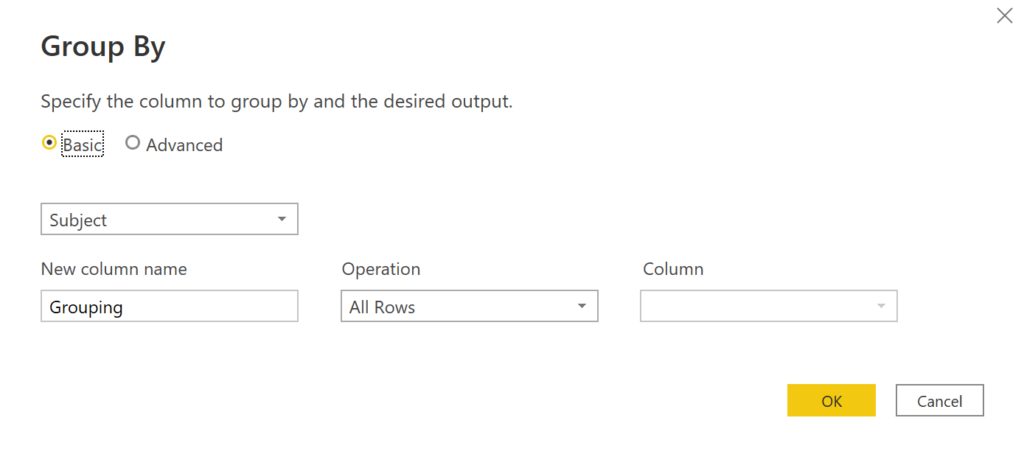
.
Now, we have a Grouping column with Table values:
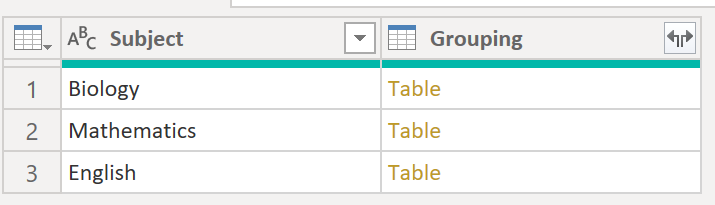
.
When clicking on a cell in the Grouping column, you can see the actual data of the table in the lower left corner:
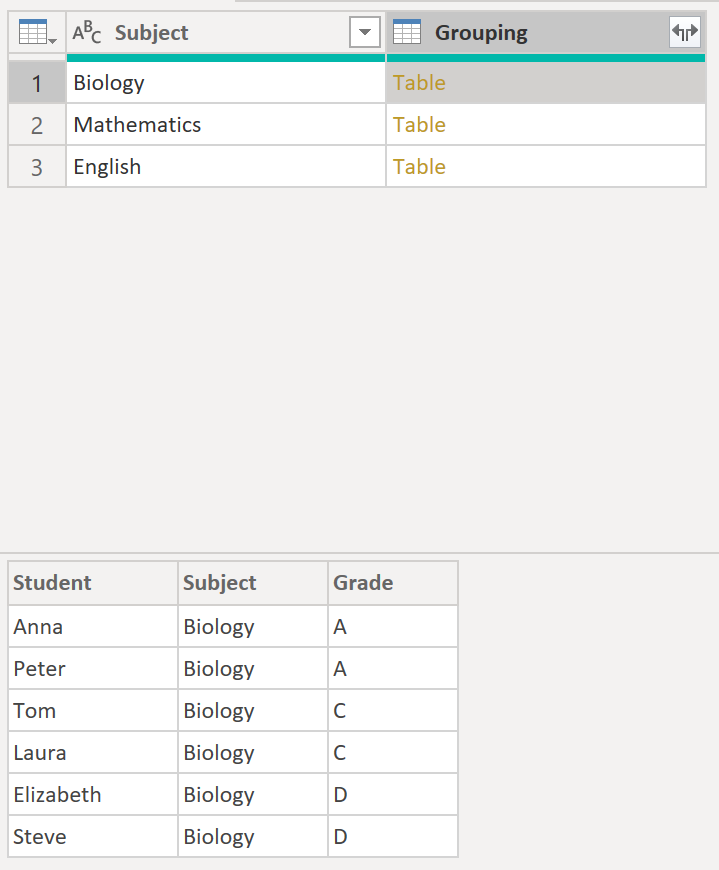
.
In order to be able to create a dense rank, where Anna and Peter would get a 1, Tom and Laura a 2 and Elizabeth and Steve a 3, we need to do an additional grouping on Grade (see option b). However, if this case does not apply to yours and you just need to create an index from 1 to 6, use the following code when creating a Custom column (see option a).
.
option a:
Table.AddIndexColumn ( [Grouping], "Index", 1 )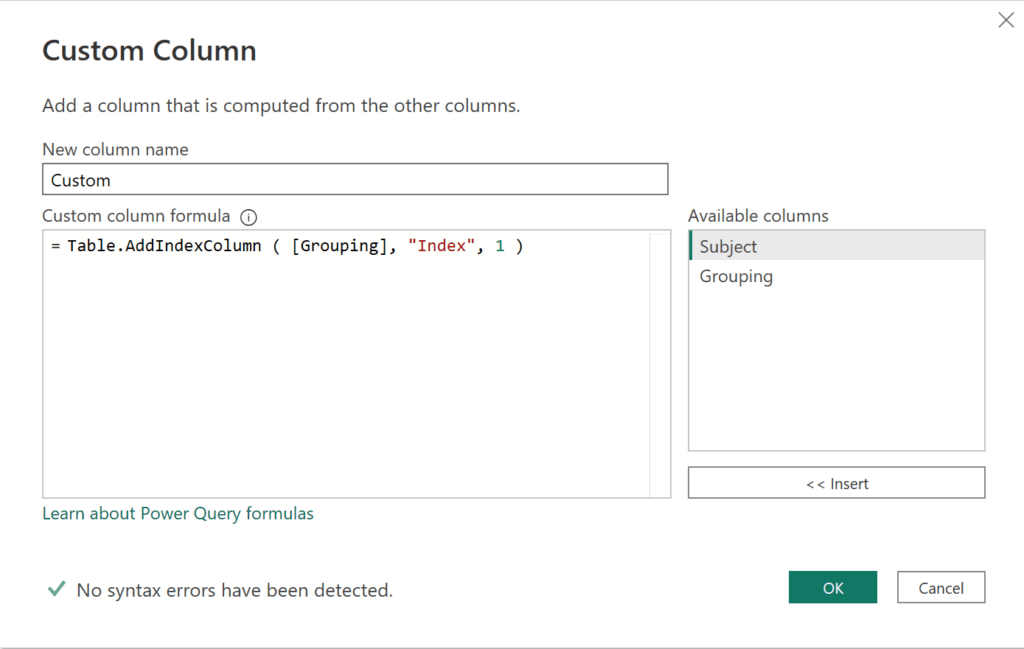
.
Right click on the new Custom column and press Remove Other Columns:
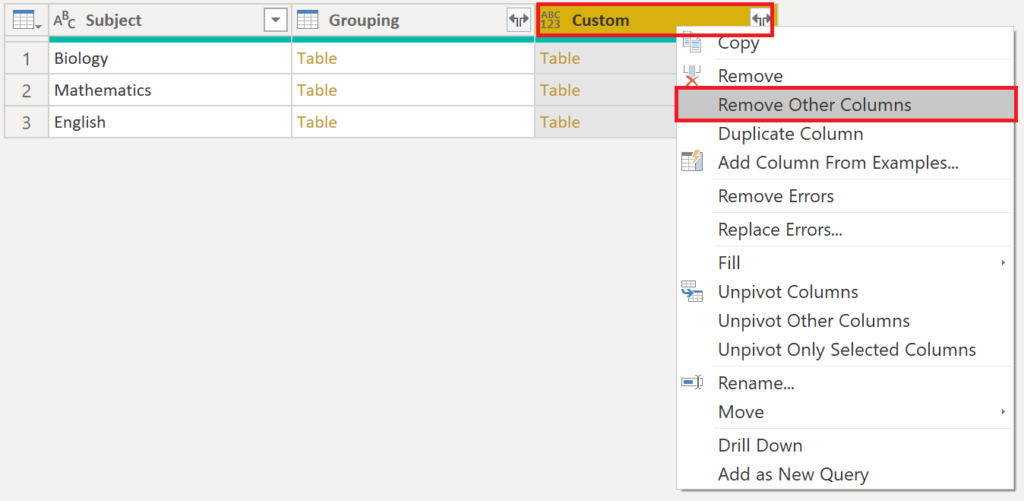
.
Click on the two arrows and expand all columns:
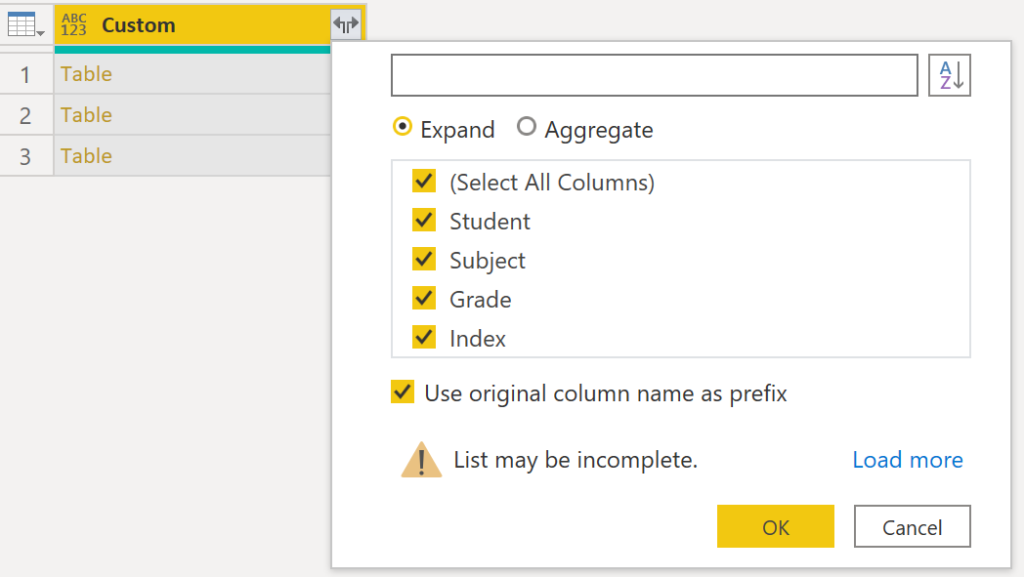
.
Voilà:
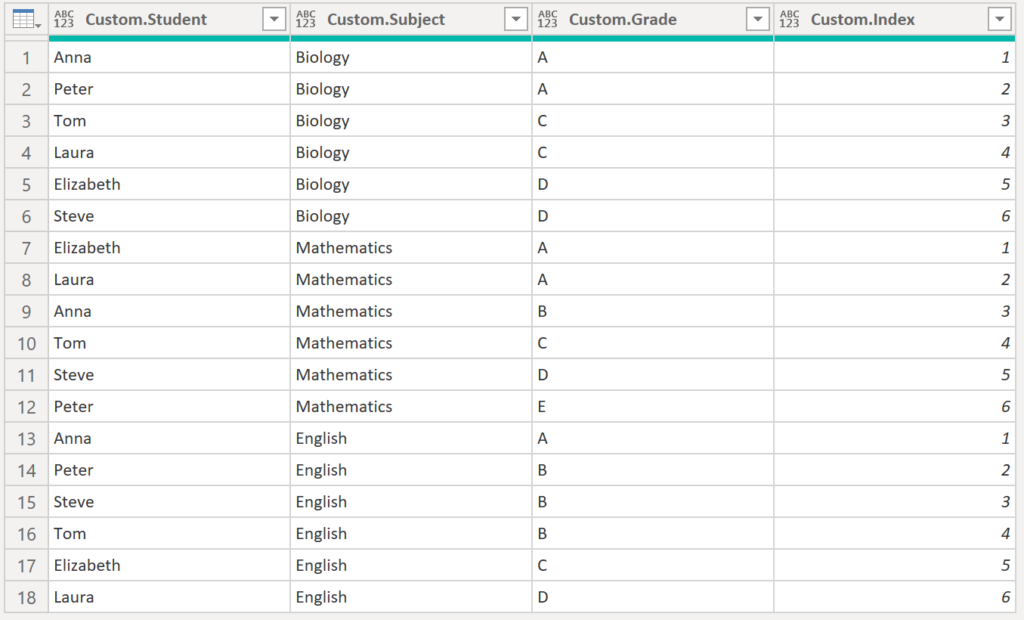
.
Here the code in advanced editor:
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("bZBBDsIgEEXvwrqXoJWdJia6I12MZlJIKCTtaKKntzY19CM78t4AD6xVOkZSjWp9Cml4LSut+saqaxqBdiu9CD8Z+GHlZxaeKqeY4N90Y3GVPUd6TFS5Yws6kTgeSfx9/g7totBgGDqMQ2f+AtFriKy5LdTEIfjZFT+XaQuBJf/FlXwfll0HUZkvD+0/", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [Student = _t, Subject = _t, Grade = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"Student", type text}}),
#"Sorted Rows" = Table.Sort(#"Changed Type",{{"Grade", Order.Ascending}}),
#"Grouped Rows" = Table.Group(#"Sorted Rows", {"Subject"}, {{"Grouping", each _, type table [Student=nullable text, Subject=nullable text, Grade=nullable text]}}),
#"Added Index" = Table.AddColumn(#"Grouped Rows", "Index", each Table.AddIndexColumn ( [Grouping], "Index", 1 )),
#"Removed Columns" = Table.RemoveColumns(#"Added Index",{"Subject", "Grouping"}),
#"Expanded Index" = Table.ExpandTableColumn(#"Removed Columns", "Index", {"Student", "Subject", "Grade", "Index"}, {"Student", "Subject", "Grade", "Index"})
in
#"Expanded Index".
However, as described above, this approach does not provide dense ranking. Let’s try to create a dense ranking instead by doing an additional grouping on grades with the following starting position:
option b:
.
We need to create a Subgrouping on the Grouping, before we can create the index. I found the easiest way to get there is by doing it just for one member of the Grouping (i.e. Biology) and afterwards align the code so it will work for all.
So, click on the table in Grouping in the Biology row to open the table for that grouping:
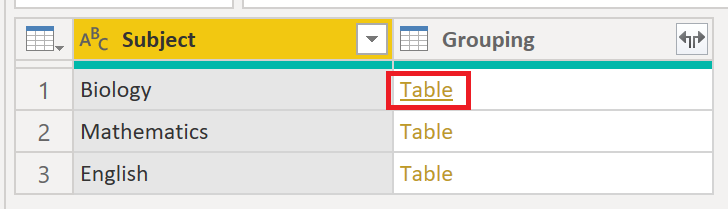
.
Then, we need to right-click on the Grade column and press Group By and fill in the fields as below:
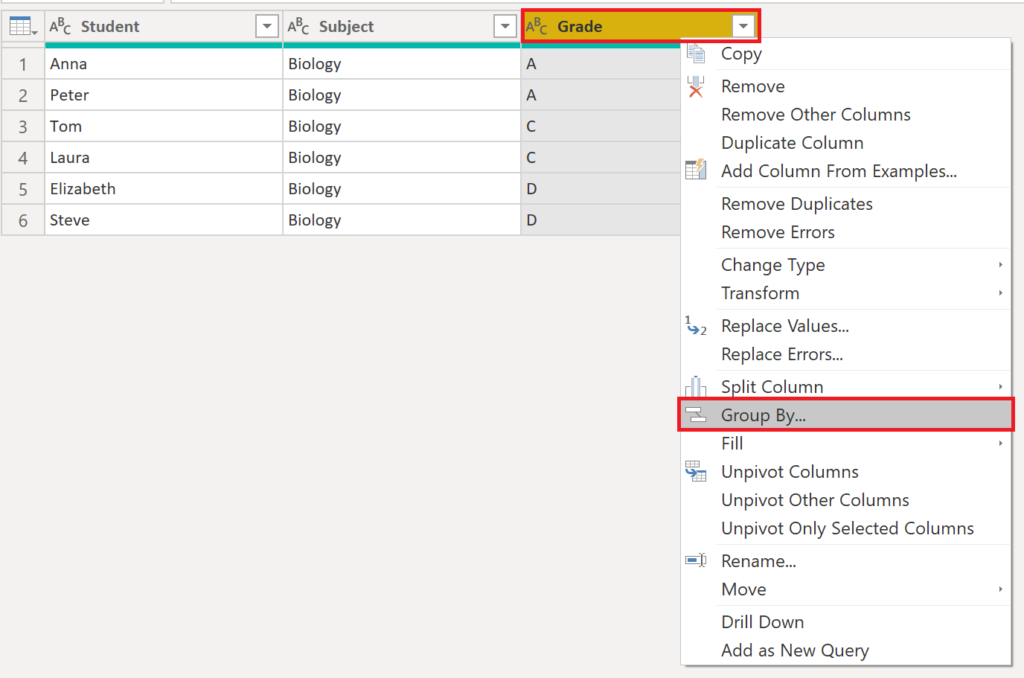
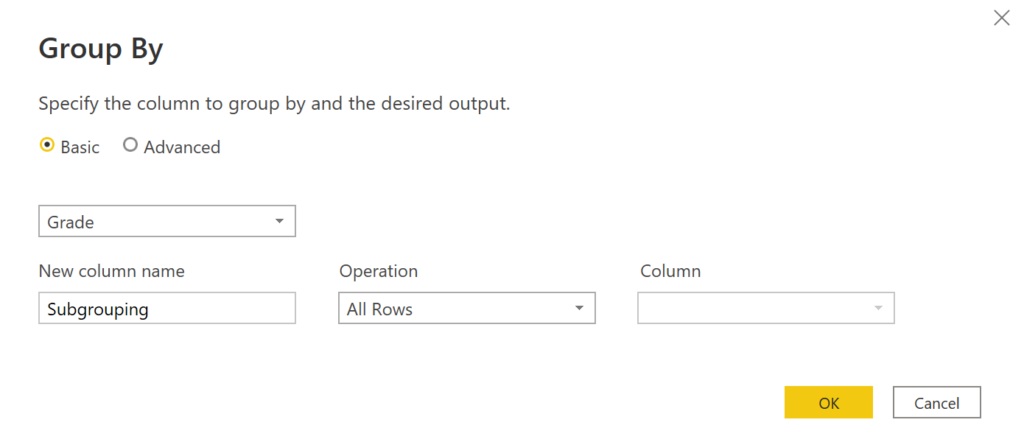
.
Now, create the index column:
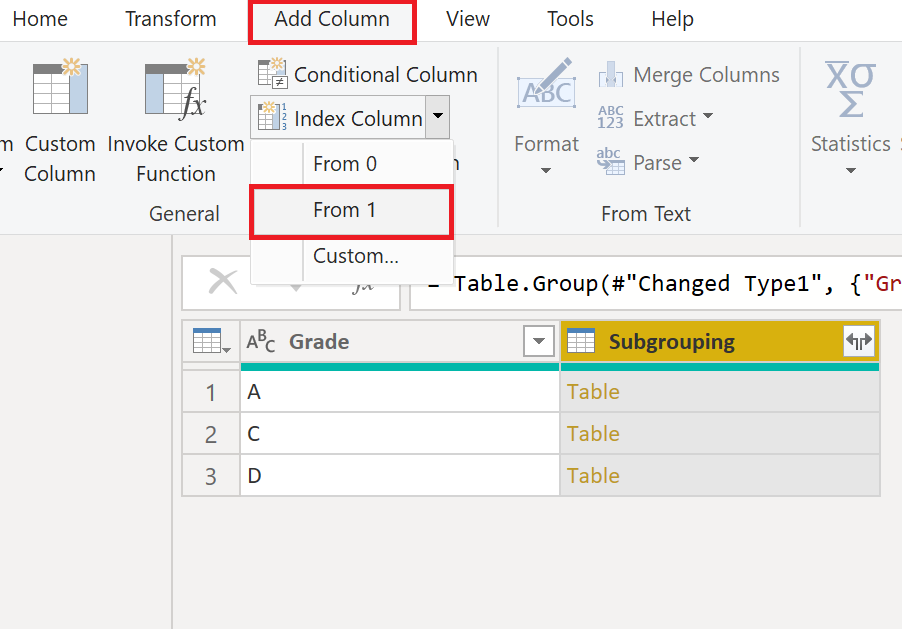
.
Next, click on the expand button (the two arrows) to retrieve the result:


.
Looks good! But we have only done it for Biology. To apply all the changes to the other groups, it’s going to get a bit dirty and hacky in the advanced editor… But don’t worry, we will get there! Let’s start with opening the advanced editor:
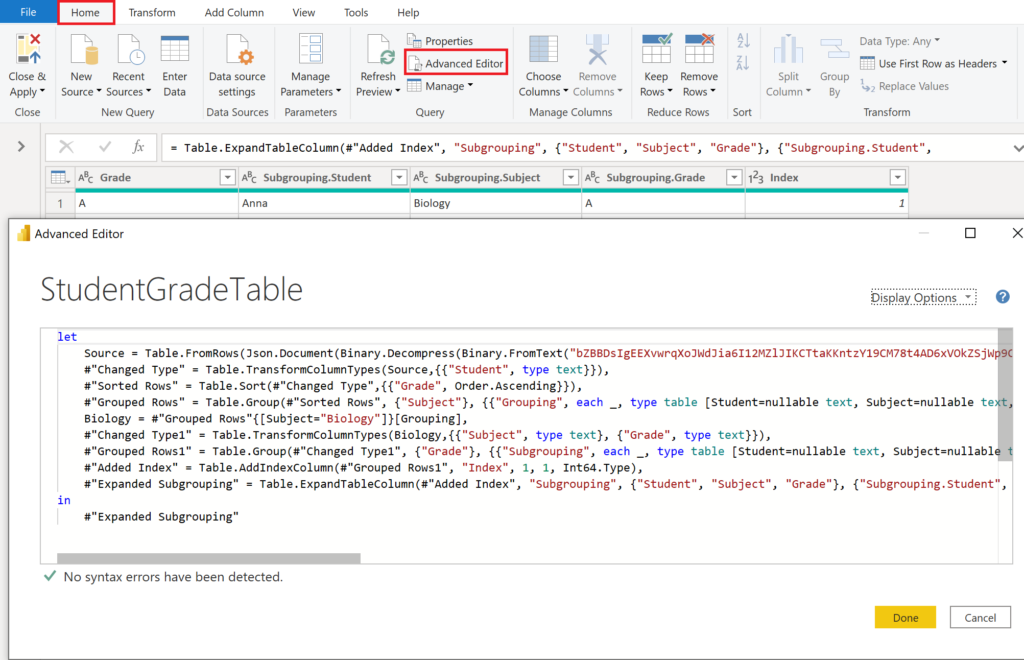
.
Essentially, we are trying to use an inner query that substitutes all the stuff we did to the Biology column:
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("bZBBDsIgEEXvwrqXoJWdJia6I12MZlJIKCTtaKKntzY19CM78t4AD6xVOkZSjWp9Cml4LSut+saqaxqBdiu9CD8Z+GHlZxaeKqeY4N90Y3GVPUd6TFS5Yws6kTgeSfx9/g7totBgGDqMQ2f+AtFriKy5LdTEIfjZFT+XaQuBJf/FlXwfll0HUZkvD+0/", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [Student = _t, Subject = _t, Grade = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"Student", type text}}),
#"Sorted Rows" = Table.Sort(#"Changed Type",{{"Grade", Order.Ascending}}),
#"Grouped Rows" = Table.Group(#"Sorted Rows", {"Subject"}, {{"Grouping", each _, type table [Student=nullable text, Subject=nullable text, Grade=nullable text]}}),
Biology = #"Grouped Rows"{[Subject="Biology"]}[Grouping],
#"Changed Type1" = Table.TransformColumnTypes(Biology,{{"Subject", type text}, {"Grade", type text}}),
#"Grouped Rows1" = Table.Group(#"Changed Type1", {"Grade"}, {{"Subgrouping", each _, type table [Student=nullable text, Subject=nullable text, Grade=nullable text]}}),
#"Added Index" = Table.AddIndexColumn(#"Grouped Rows1", "Index", 1, 1, Int64.Type),
#"Expanded Subgrouping" = Table.ExpandTableColumn(#"Added Index", "Subgrouping", {"Student", "Subject", "Grade"}, {"Subgrouping.Student", "Subgrouping.Subject", "Subgrouping.Grade"})
in
#"Expanded Subgrouping".
Do the following for the coloured parts:
1. substitute each _, with each SubGroupAddIndex(_)
2. substitute Biology = #"Grouped Rows"{[Subject="Biology"]}[Grouping], with SubGroupAddIndex = (Table as table) as table =>
3. substitute #"Changed Type1" = Table.TransformColumnTypes(Biology,{{"Subject", type text}, {"Grade", type text}}), with let
4. substitute #"Changed Type1" with Table
5. substitute "Subgrouping.Student", "Subgrouping.Subject" with "Student", "Subject"
6. add a comma to #"Expanded Subgrouping"
7. add to the end: #”Expanded Groups” = Table.ExpandTableColumn(#”Grouped Rows”, “Grouping”, {“Student”, “Grade”, “Index”}, {“Student”, “Grade”, “Index”}) in #”Expanded Groups”
Here is how the result should look like in advanced editor after the substitutions:
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("bZBBDsIgEEXvwrqXoJWdJia6I12MZlJIKCTtaKKntzY19CM78t4AD6xVOkZSjWp9Cml4LSut+saqaxqBdiu9CD8Z+GHlZxaeKqeY4N90Y3GVPUd6TFS5Yws6kTgeSfx9/g7totBgGDqMQ2f+AtFriKy5LdTEIfjZFT+XaQuBJf/FlXwfll0HUZkvD+0/", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [Student = _t, Subject = _t, Grade = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"Student", type text}}),
#"Sorted Rows" = Table.Sort(#"Changed Type",{{"Grade", Order.Ascending}}),
#"Grouped Rows" = Table.Group(#"Sorted Rows", {"Subject"}, {{"Grouping", each SubGroupAddIndex(_), type table [Student=nullable text, Subject=nullable text, Grade=nullable text]}}),
SubGroupAddIndex = (Table as table) as table =>
let
#"Grouped Rows1" = Table.Group(Table, {"Grade"}, {{"Subgrouping", each _, type table [Student=nullable text, Subject=nullable text, Grade=nullable text]}}),
#"Added Index" = Table.AddIndexColumn(#"Grouped Rows1", "Index", 1, 1, Int64.Type),
#"Expanded Subgrouping" = Table.ExpandTableColumn(#"Added Index", "Subgrouping", {"Student", "Subject", "Grade"}, {"Student", "Subject", "Subgrouping.Grade"})
in
#"Expanded Subgrouping",
#"Expanded Groups" = Table.ExpandTableColumn(#"Grouped Rows", "Grouping", {"Student", "Grade", "Index"}, {"Student", "Grade", "Index"})
in
#"Expanded Groups".
And here the outcome:
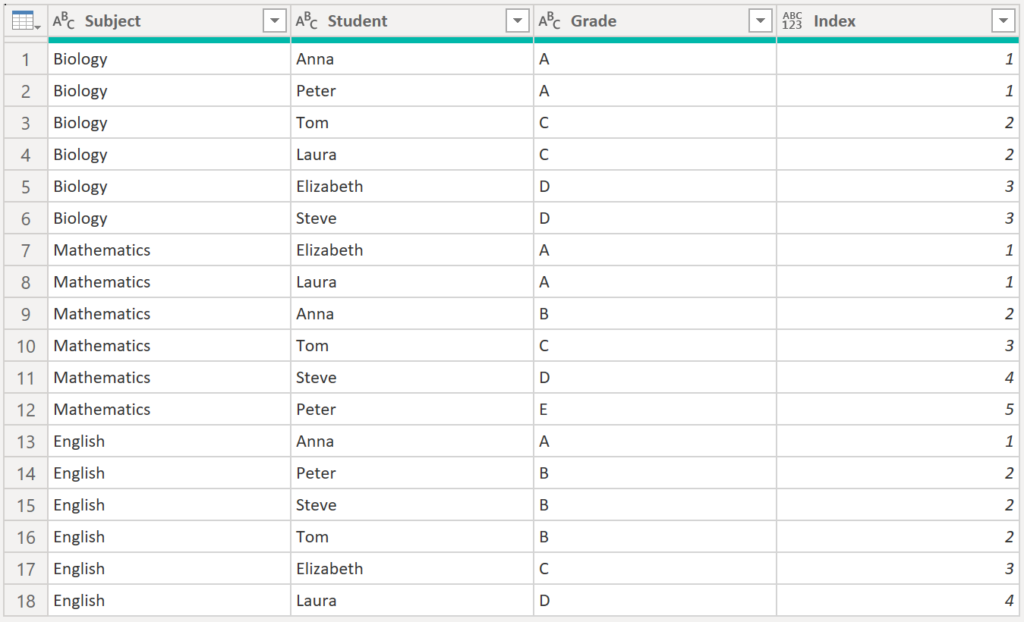
.
Once again, it is not that trivial if you need to do subgroupings, meaning doing a group by on an already grouped column. However, it is doable and when having done the transformation for one of the elements, it is easier to create the generic one.
.
4. Check if values of one column exist in another column
We’d like to find out for each row in column1 whether it exists in column2 – much like the Excel lookup function. The result we’d like to save in a separate column (LookupResult):
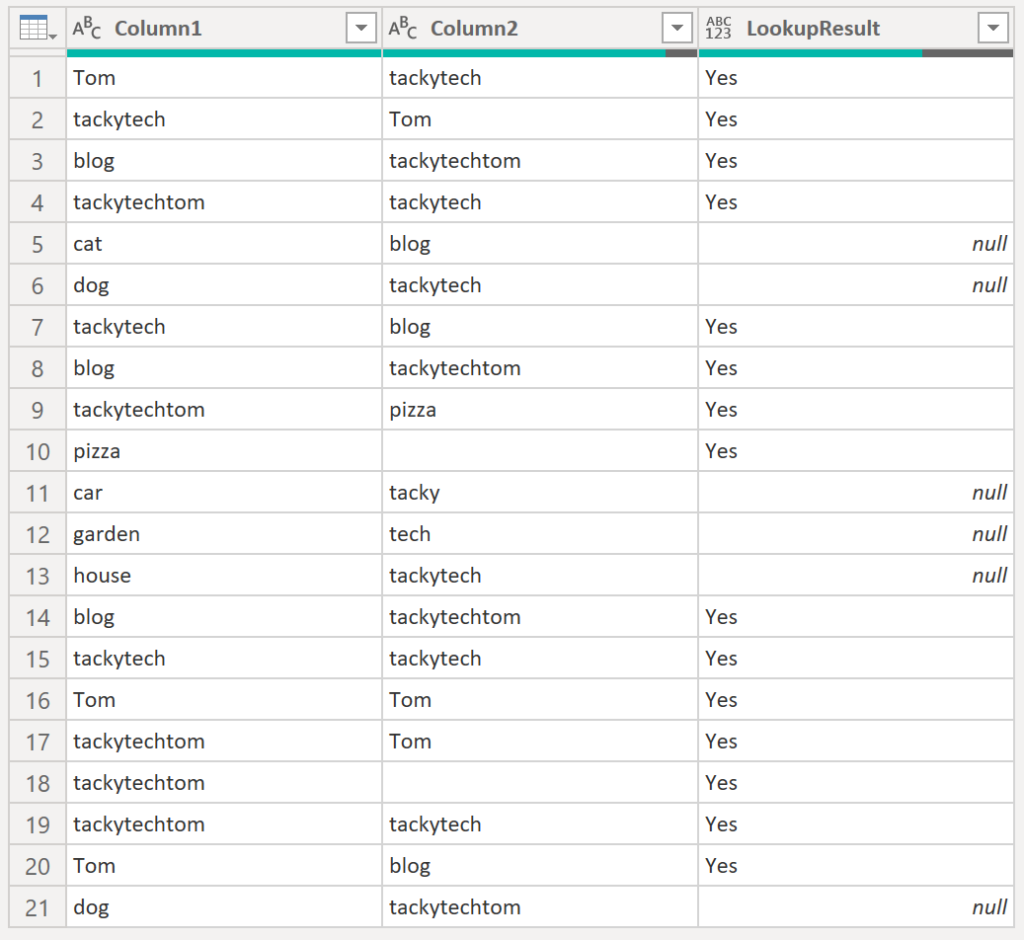
.
To get that column, create a custom column and apply the following code:
if List.Contains(#"Changed Type"[Column2] , [Column1]) = true then "Yes" else null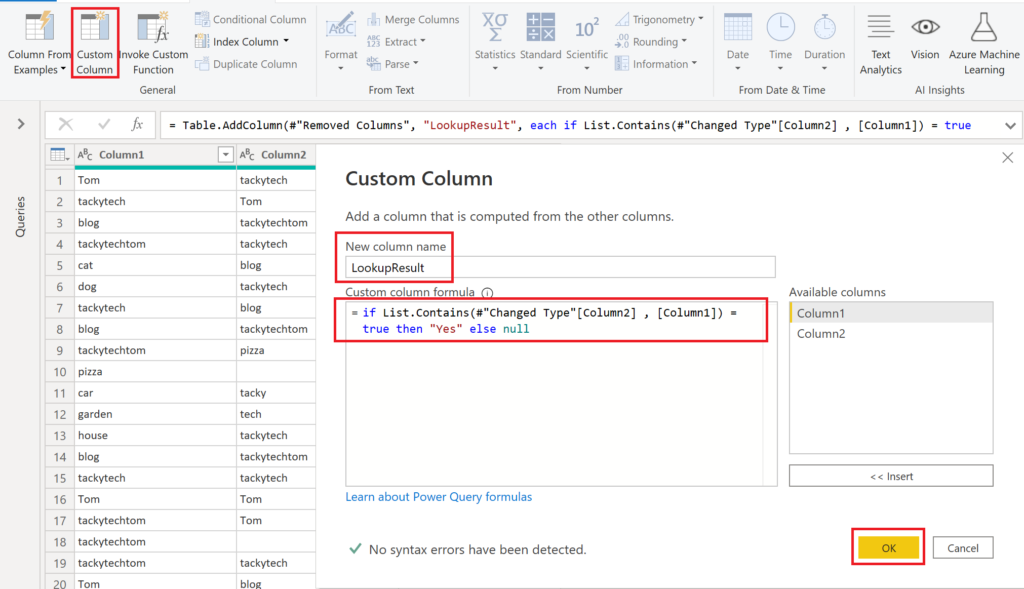
.
Here the Power Query code:
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("lVHLDsMgDPuXnPs5uyEOGaB22oOqyw7r1w8ItCWlk3ojtrHsRCm4+Cd0QGjuX3JmCG/QnaoAliT4+vD9Vk717zhWv2nnboNBlBikMEm/RFmBZZmM1cpynHG8zTO2wjGR9UlQkAiWTAanRcMbiWiPk3WvopM9Bv95u6MmZzcpfNY6fJ3NjYTlyjfIk8er+7FzLrIUs397gdY/", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [Column1 = _t, Column2 = _t, Column3 = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"Column1", type text}, {"Column2", type text}, {"Column3", type text}}),
#"Removed Columns" = Table.RemoveColumns(#"Changed Type",{"Column3"}),
#"Added Custom" = Table.AddColumn(#"Removed Columns", "LookupResult", each if List.Contains(#"Changed Type"[Column2] , [Column1]) = true then "Yes" else null)
in
#"Added Custom"Note, you can also solve this issue in DAX.
.
5. Return table: one row of latest version / status per group
Our goal is to transform the following table into only one row per group (Email). That row shall show the latest version / status.

.
We start with a group by:
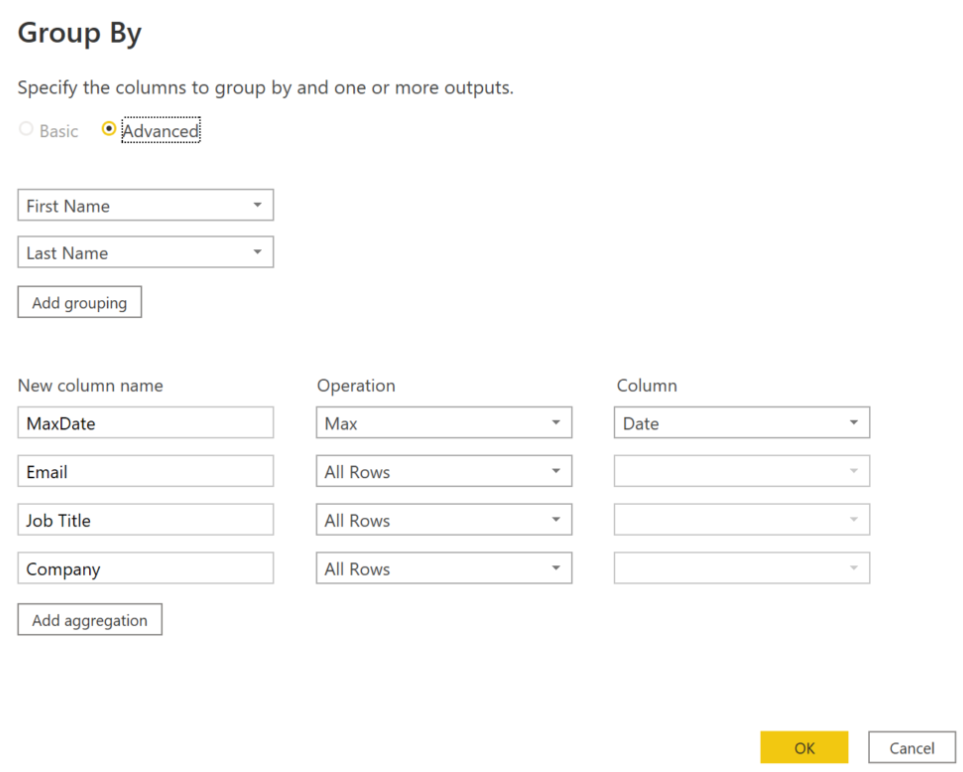

.
Next, we expand the Email column by clicking on the two arrows on the top right:

.
Then, we add a custom column where we match the new date column from the expanded email step with the MaxDate. We return 1 if there is a match, otherwise 0:
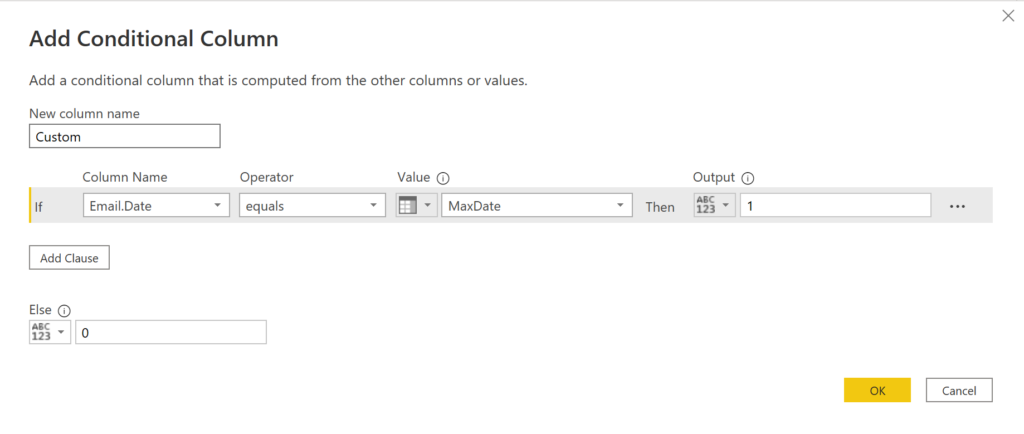
.
Lastly, we filter for 1 in that new column, remove the columns we do not need and rename the remaining ones if necessary:

.
Here the Power Query code:
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45W8srPyFPSUXLJTwWSYQFAIislP9UhCyhcnJ+nl5yfCxTygvCALEN9Q30jI6VYHdJ1grUaYmpVwKtTwTMvWQ+k3QiHdmdXf6IMMIK6PBYA", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [#"First Name" = _t, #"Last Name" = _t, #"Job Title" = _t, Email = _t, Company = _t, Date = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"First Name", type text}, {"Last Name", type text}, {"Job Title", type text}, {"Email", type text}, {"Company", type text}, {"Date", type date}}),
#"Grouped Rows" = Table.Group(#"Changed Type", {"First Name", "Last Name"}, {{"MaxDate", each List.Max([Date]), type nullable date}, {"Email", each _, type table [First Name=nullable text, Last Name=nullable text, Job Title=nullable text, Email=nullable text, Company=nullable text, Date=nullable date]}, {"Job Title", each _, type table [First Name=nullable text, Last Name=nullable text, Job Title=nullable text, Email=nullable text, Company=nullable text, Date=nullable date]}, {"Company", each _, type table [First Name=nullable text, Last Name=nullable text, Job Title=nullable text, Email=nullable text, Company=nullable text, Date=nullable date]}}),
#"Expanded Email" = Table.ExpandTableColumn(#"Grouped Rows", "Email", {"First Name", "Last Name", "Job Title", "Email", "Company", "Date"}, {"Email.First Name", "Email.Last Name", "Email.Job Title", "Email.Email", "Email.Company", "Email.Date"}),
#"Added Custom" = Table.AddColumn(#"Expanded Email", "Custom", each if [Email.Date] = [MaxDate] then 1 else 0),
#"Filtered Rows" = Table.SelectRows(#"Added Custom", each ([Custom] = 1)),
#"Removed Columns" = Table.RemoveColumns(#"Filtered Rows",{"MaxDate", "Email.First Name", "Email.Last Name", "Job Title", "Company", "Custom"}),
#"Renamed Columns" = Table.RenameColumns(#"Removed Columns",{{"Email.Job Title", "Job Title"}, {"Email.Email", "Email"}, {"Email.Company", "Company"}, {"Email.Date", "Date"}})
in
#"Renamed Columns".
6. Return certain values from string
Let’s try to catch the marked words with the pattern “GT-%” from the strings the following column:
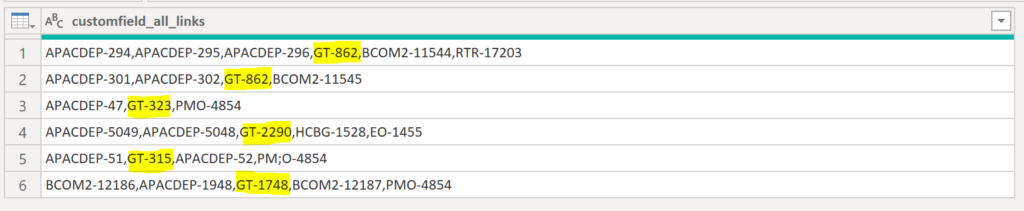
.
Add a custom custom column with the following settings:
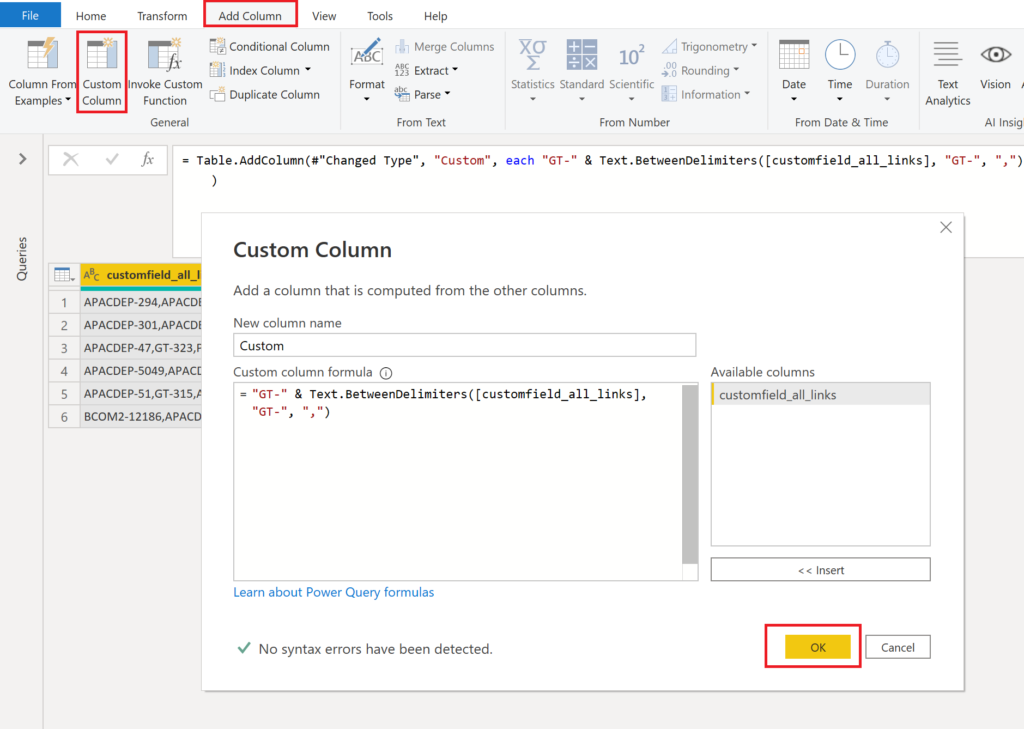
.
Result:
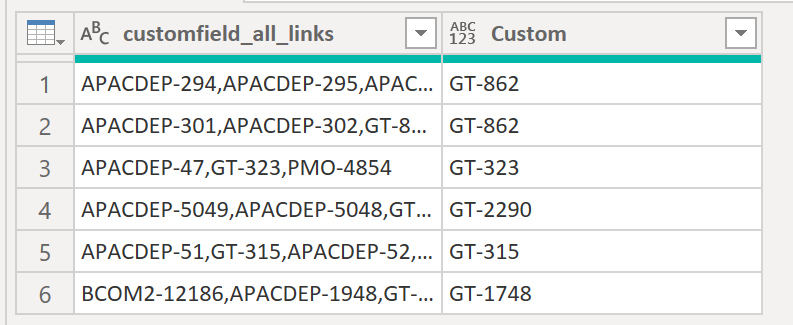
.
Here the Power Query code:
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("ZY9LDoMwDETvwtqWYsfOR10BRXSDEiF2iPtfo0CrJlFXHsvPM/a+d33ux+eUkaNA0VppB/OGwTEMY1oYiVQE1m1F8mxsd0AxsYagaP5f1AYXfxGWLeQloQSVZqxGIlRNuGjmaOA1DjOScoApIYm2tkq3LZUnlM+ERxXxvYgpuB9E8ZNA/qwF8NVxxxs=", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [customfield_all_links = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"customfield_all_links", type text}}),
#"Added Custom" = Table.AddColumn(#"Changed Type", "Custom", each "GT-" & Text.BetweenDelimiters([customfield_all_links], "GT-", ","))
in
#"Added Custom".
If you only need those specific values you can drop the first column. Another way would be to replace the values directly in the first column instead of creating another column and then removing the old one. Use this Power Query:
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("ZY9LDoMwDETvwtqWYsfOR10BRXSDEiF2iPtfo0CrJlFXHsvPM/a+d33ux+eUkaNA0VppB/OGwTEMY1oYiVQE1m1F8mxsd0AxsYagaP5f1AYXfxGWLeQloQSVZqxGIlRNuGjmaOA1DjOScoApIYm2tkq3LZUnlM+ERxXxvYgpuB9E8ZNA/qwF8NVxxxs=", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [customfield_all_links = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"customfield_all_links", type text}}),
#"Replaced Value" = Table.ReplaceValue(#"Changed Type",each [customfield_all_links], each "GT-" & Text.BetweenDelimiters([customfield_all_links], "GT-", ","),Replacer.ReplaceValue,{"customfield_all_links"})
in
#"Replaced Value".
Result:
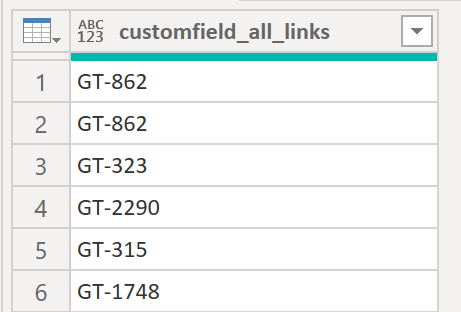
.
7. Replace values in column
Our aim is to replace all values in Attribute that have Points below 10 with a string saying “not worth to mention”.
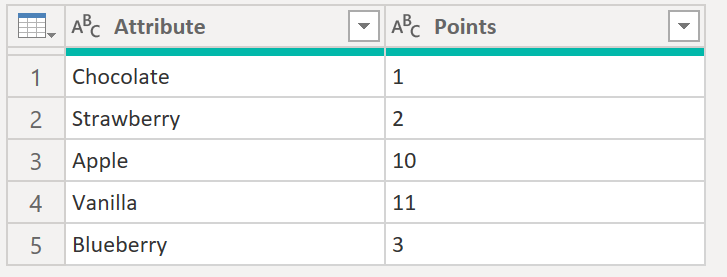
.
Since we’d like to keep the number of steps in Power Query o a minimum, we want to replace the values in the column and not create a new column. The generic code snippet for the advanced editor for replacing values would look like this:
#"Replace Values" = Table.ReplaceValue(#"Previous step",each [ColumnToReplaceValues],each PasteYourReplaceStatementHere,Replacer.ReplaceValue,{"ColumnToReplaceValues"}).
It does not seem too hard, does it? However, the PasteYourReplaceStatementHere might give you some headache. Here an easy method to fix this:
First create a custom column where you write your code:
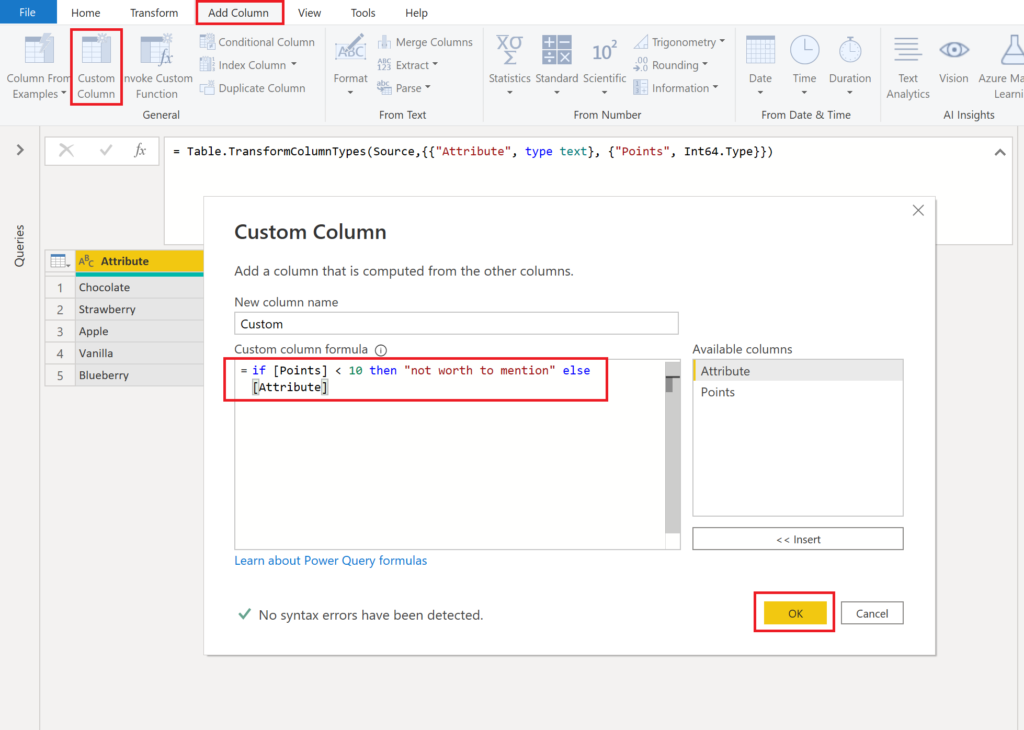
.
Then, check your results:
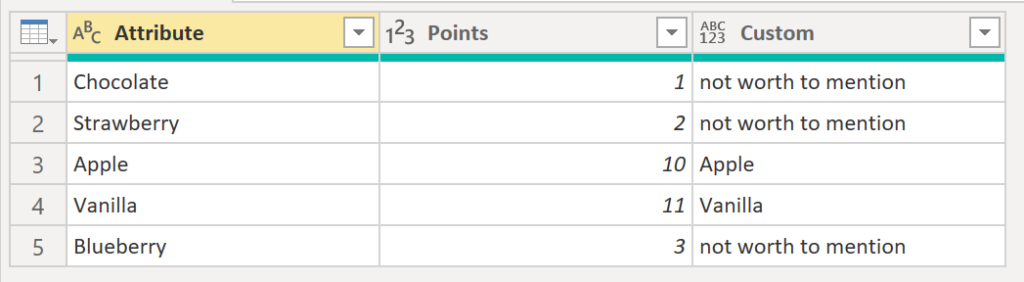
.
If you are happy with it, you are almost there. All you need to do is to substitute the bold parts from the replace snippet above. For that, open advanced editor and paste the code snippet underneath your created column:

.
Now, replace the parts accordingly:
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45Wcs7IT87PSSxJVdJRMlSK1YlWCi4pSixPSi0qqgQKGYGFHAsKcsAKDMDcsMS8zJycRJAARItTTmkqTIexUmwsAA==", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [Attribute = _t, Points = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"Attribute", type text}, {"Points", Int64.Type}}),
#"Added Custom" = Table.AddColumn(#"Changed Type", "Custom", each if [Points] < 10 then "not worth to mention" else [Attribute])
#"Replace Values" = Table.ReplaceValue(#"Previous step",each [ColumnToReplaceValues],each PasteHereYourReplaceStatement,Replacer.ReplaceValue,{"ColumnToReplaceValues"})
in
#"Added Custom"1. Substitute the Previous step with Changed Type
2. Substitute PasteHereYourReplaceStatement with the logic written in your custom column if [Points] < 10 then “not worth to mention” else [Attribute]
3. Substitute ColumnToReplaceValues with Attribute
4. Substitute Added Custom with Replace Values
5. Remove the #”Added Custom” step by deleting the whole line.
.
You should end up with the following code:
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45Wcs7IT87PSSxJVdJRMlSK1YlWCi4pSixPSi0qqgQKGYGFHAsKcsAKDMDcsMS8zJycRJAARItTTmkqTIexUmwsAA==", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [Attribute = _t, Points = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"Attribute", type text}, {"Points", Int64.Type}}),
#"Replace Values" = Table.ReplaceValue(#"Changed Type",each [Attribute],each if [Points] < 10 then "not worth to mention" else [Attribute],Replacer.ReplaceValue,{"Attribute"})
in
#"Replace Values".
Result:
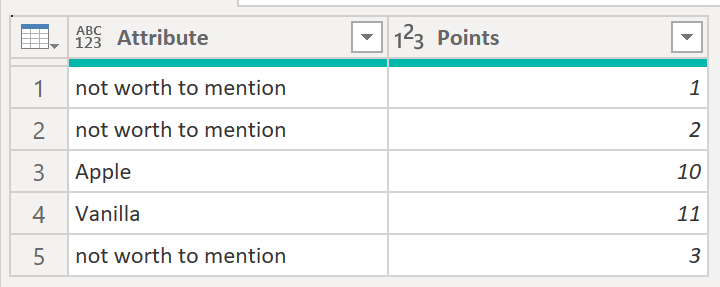
.
Admittedly, in this case we could have probably written the logic directly into the snippet without creating a custom column. However, there might be cases where you wanna test different scenarios in your logic and you might feel not comfortable to do this straight in the advanced editor. In that circumstance, just create a custom column and take it from there.
.
8. Split by multiple delimiters
We are faced with the following string and would like to split the column by any of the following delimiters: [ ] \ _ ^
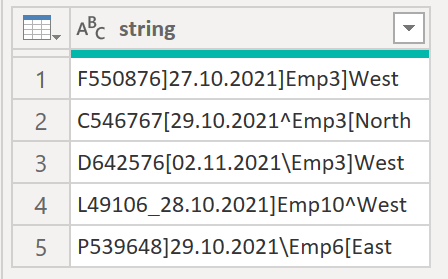
.
All we need to do is to add the following code snippet to the advanced editor. The key function is Splitter.SplitTextByAnyDelimiter()
#"Split Column by Delimiter" = Table.SplitColumn(Source, "string", Splitter.SplitTextByAnyDelimiter({"[","]","\", "_", "^"}, QuoteStyle.None), {"Column1.1", "Column1.2", "Column1.3", "Column1.4"}) .
Result:

.
Here the Power Query code:
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("Vc09C8JADIDh/3JzOZL0ktzNWicRtw5pWjoILmLR/n+kB37tD+9rFg7MkFWcNCJEAkLvbkvr/eW5Bm8s7DiJihqVNxg3YKf7Y71WsZdErGJAEbGKYfhvHFNBkIny7wNh/IAzt0VS9u+kJsS6eRP+Ag==", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [string = _t]),
#"Split Column by Delimiter" = Table.SplitColumn(Source, "string", Splitter.SplitTextByAnyDelimiter({"[","]","\", "_", "^"}, QuoteStyle.None), {"Column1.1", "Column1.2", "Column1.3", "Column1.4"})
in
#"Split Column by Delimiter".
9. Calculate difference between rows
The task is to calculate the difference of the dates between each row for each category:
.
We start with creating an index column (From 0).
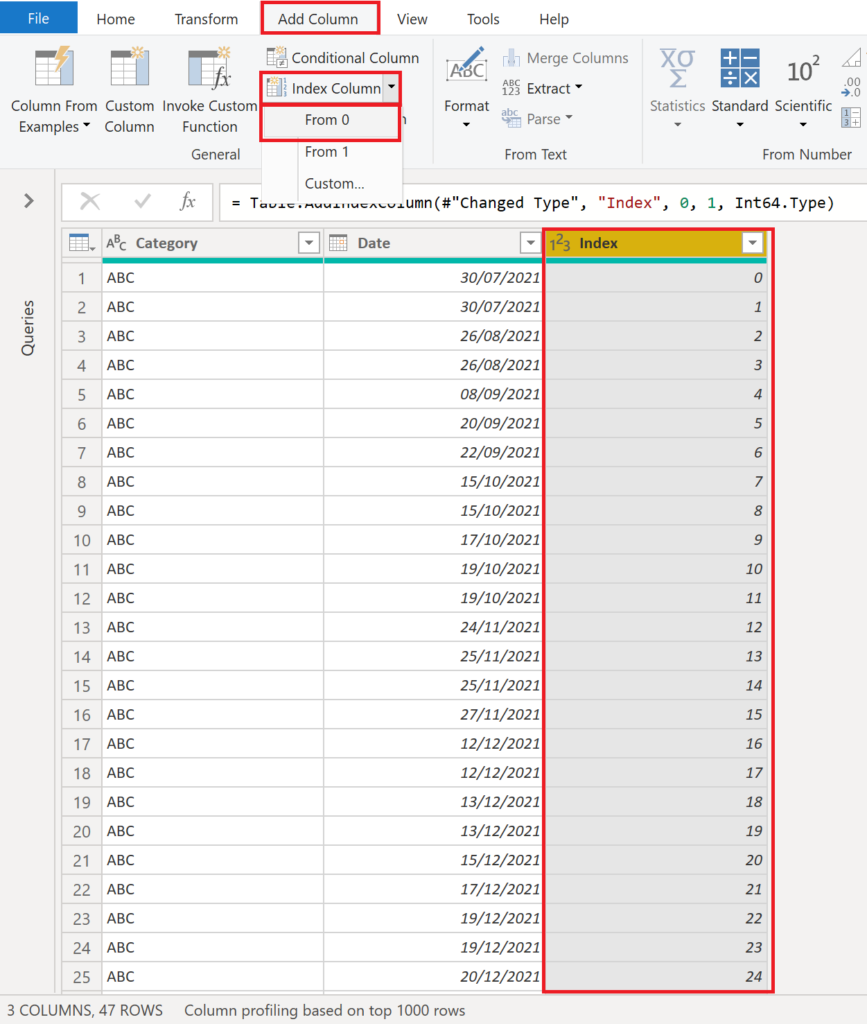
.
Then, we create another index column, but this time from 1:
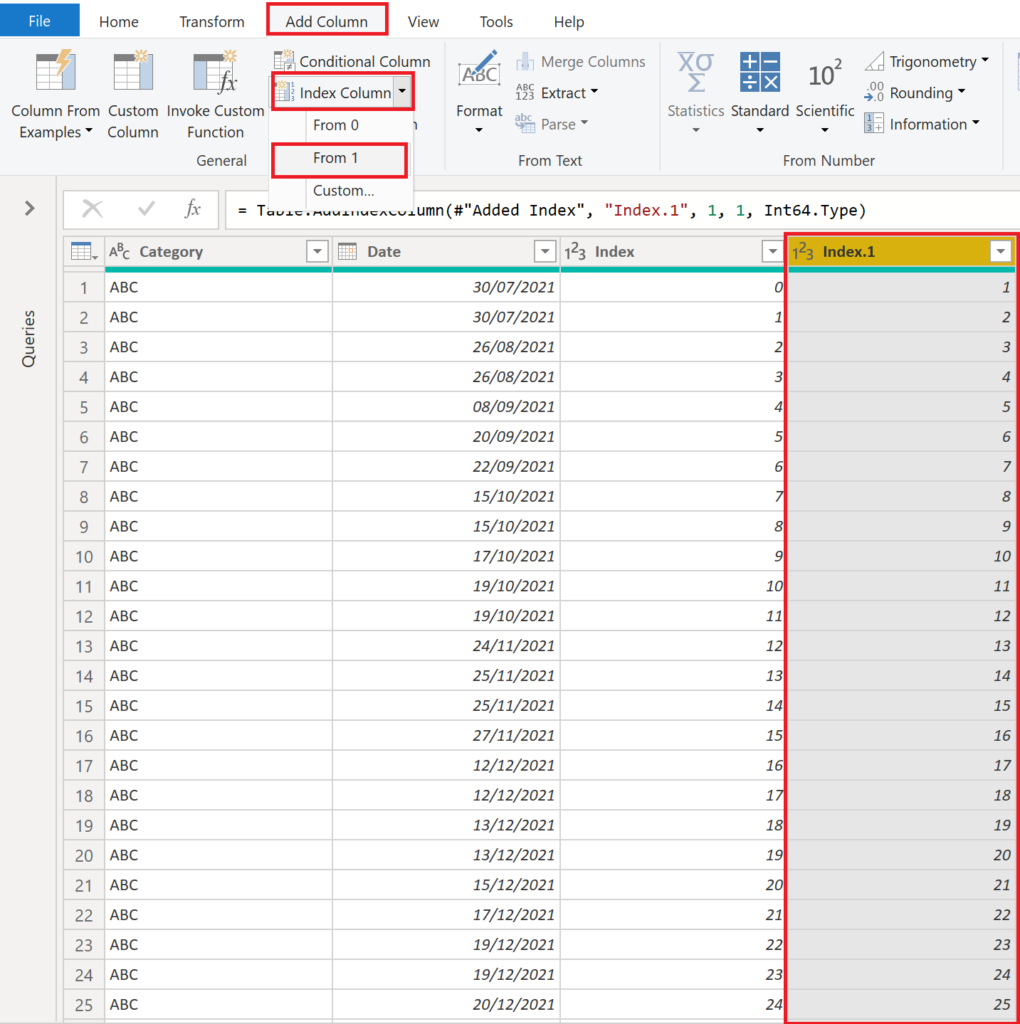
.
Next, we need to merge the table on itself by using the two created index columns:
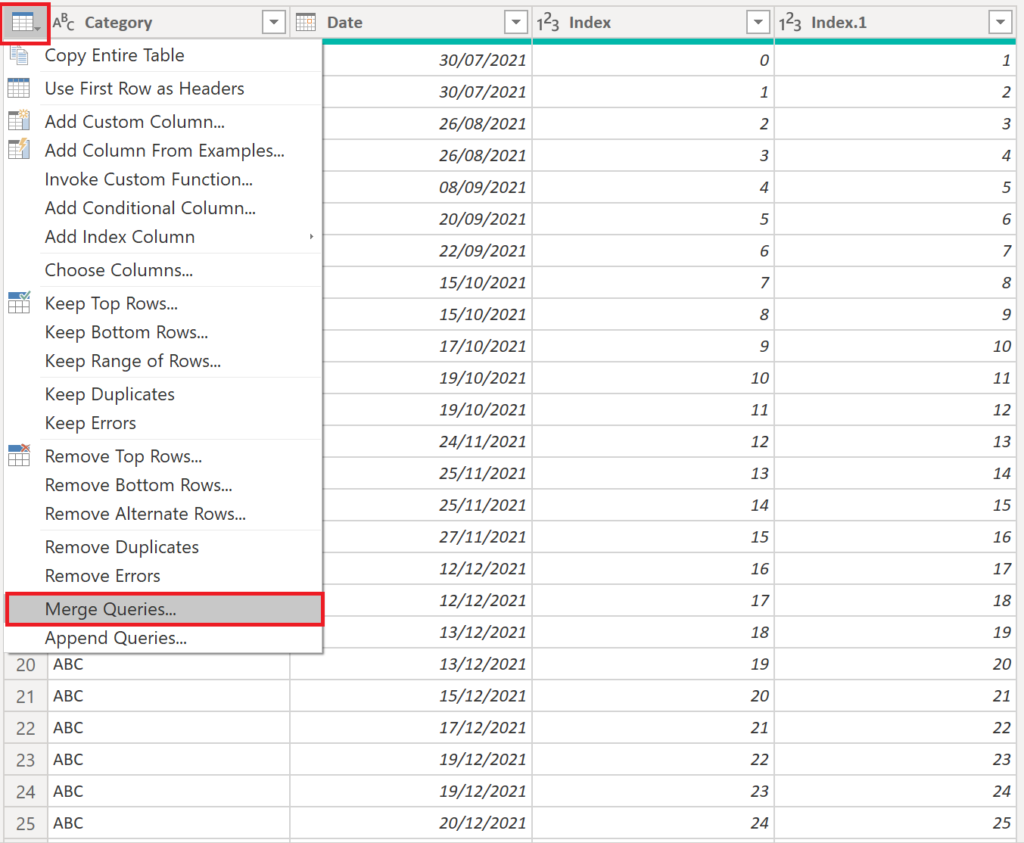
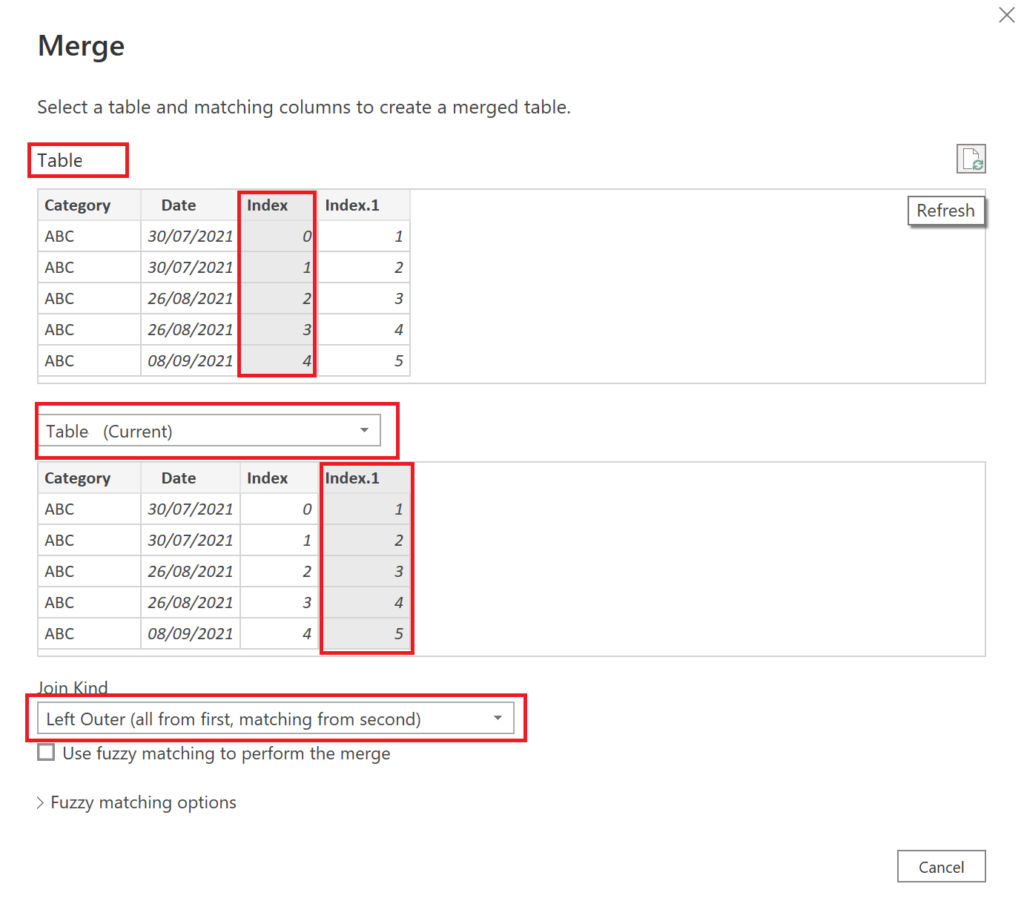
.
You’ll notice a new table column. Click on the two arrows on the top right and choose Date:
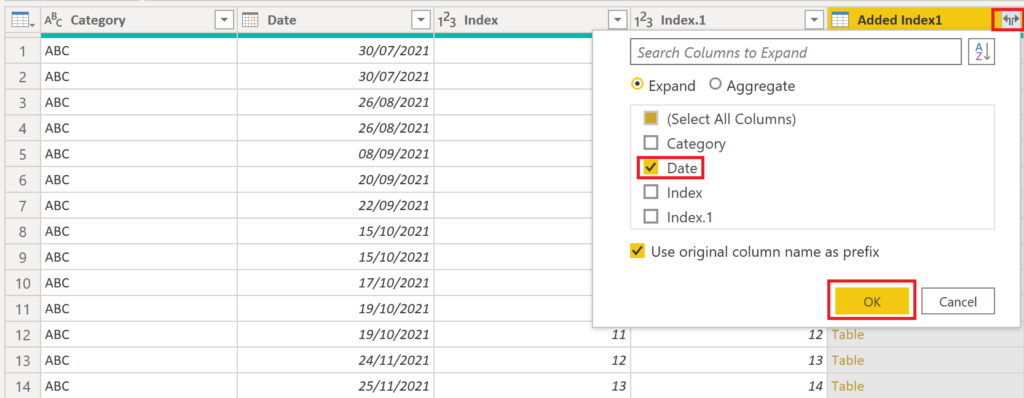
.
For each row, the new date column (Added Index1.Date) shows the next date of the following row:
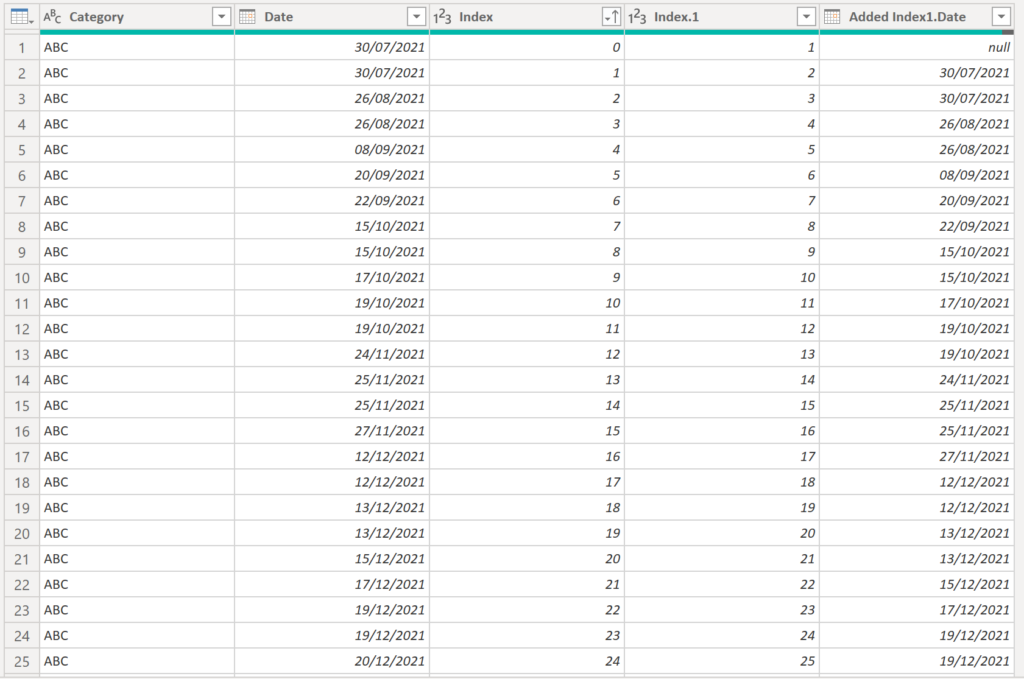
.
All that is left, is to calculate the difference between Date and Added Index1.Date (we use the formula Duration.Days) and remove all unnecessary columns:
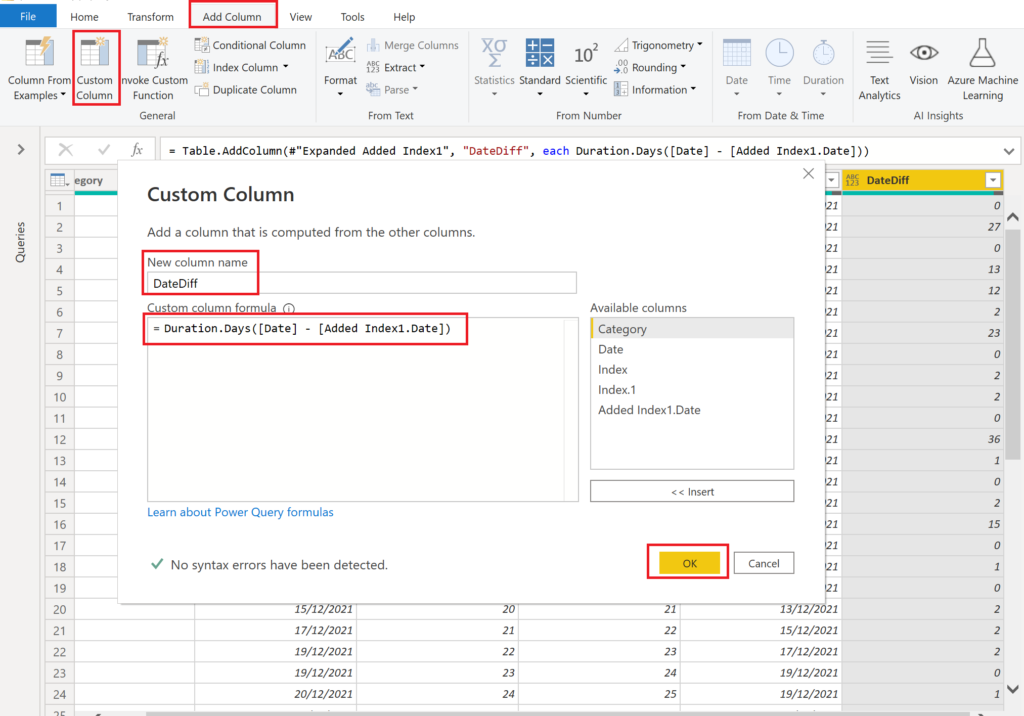
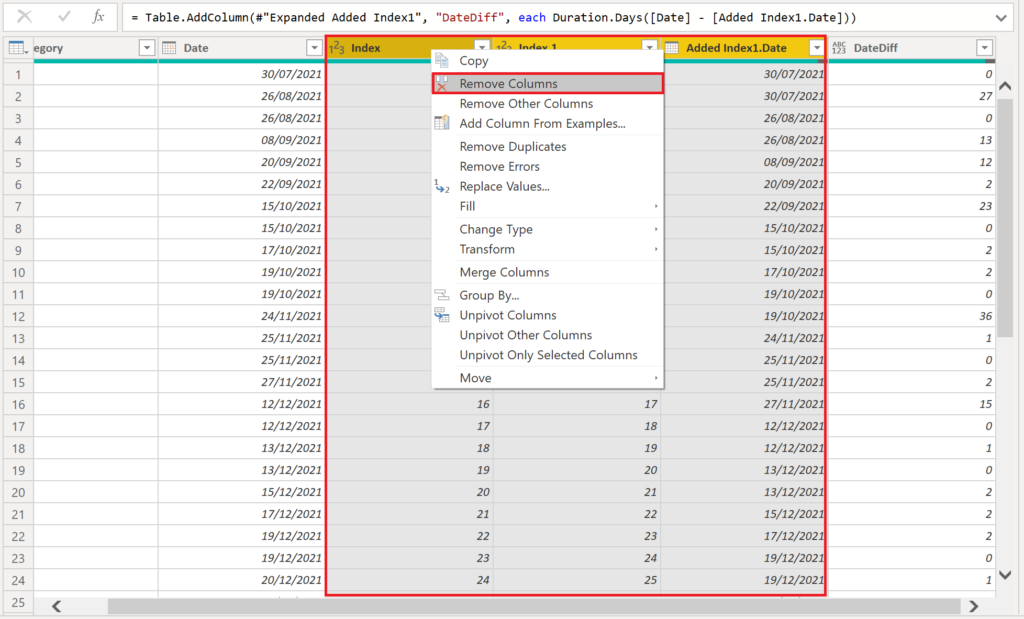
.
Result:
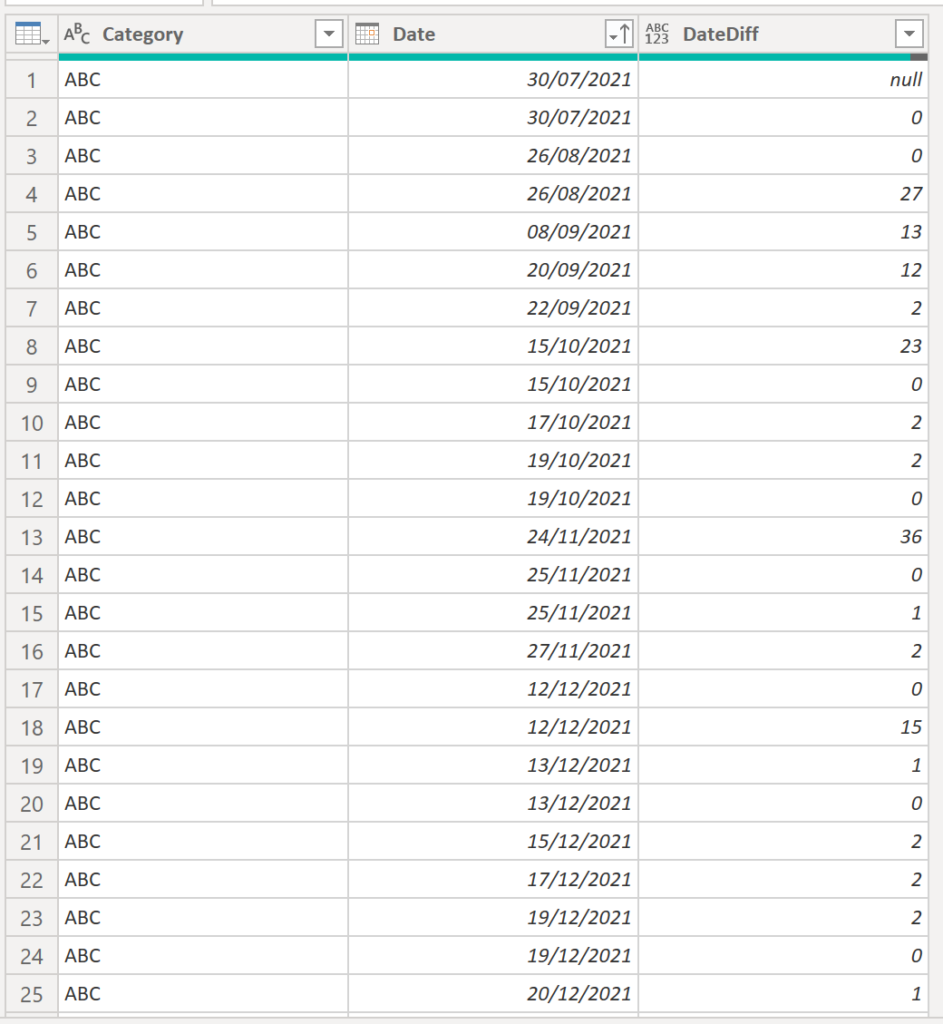
.
Obviously, this way works for any row by row calculations. Following, the Power Query code:
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("tdFLCsMwDATQu3gd0Ggc1/Ey7TFC7n+NikI2ydAKQmFWD4F+21bW56tMpcLQjaCXffqKfBiWFIZgXCqhkAK9mSOHXeHIImdzv2BLYxfotEgKaxqbwq5wZDHeIdAFoho+a/InNoXjD+gWA5yR93AR6KqRxiqQElWjPGK2iLj8gfsb", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [Category = _t, Date = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"Date", type date}}),
#"Added Index" = Table.AddIndexColumn(#"Changed Type", "Index", 0, 1, Int64.Type),
#"Added Index1" = Table.AddIndexColumn(#"Added Index", "Index.1", 1, 1, Int64.Type),
#"Merged Queries" = Table.NestedJoin(#"Added Index1", {"Index"}, #"Added Index1", {"Index.1"}, "Added Index1", JoinKind.LeftOuter),
#"Expanded Added Index1" = Table.ExpandTableColumn(#"Merged Queries", "Added Index1", {"Date"}, {"Added Index1.Date"}),
#"Added Custom" = Table.AddColumn(#"Expanded Added Index1", "DateDiff", each Duration.Days([Date] - [Added Index1.Date])),
#"Removed Columns" = Table.RemoveColumns(#"Added Custom",{"Index", "Index.1", "Added Index1.Date"})
in
#"Removed Columns".
10. Create comma separated list per group
The requirement is to return a delimiter separated list of the children per parent:
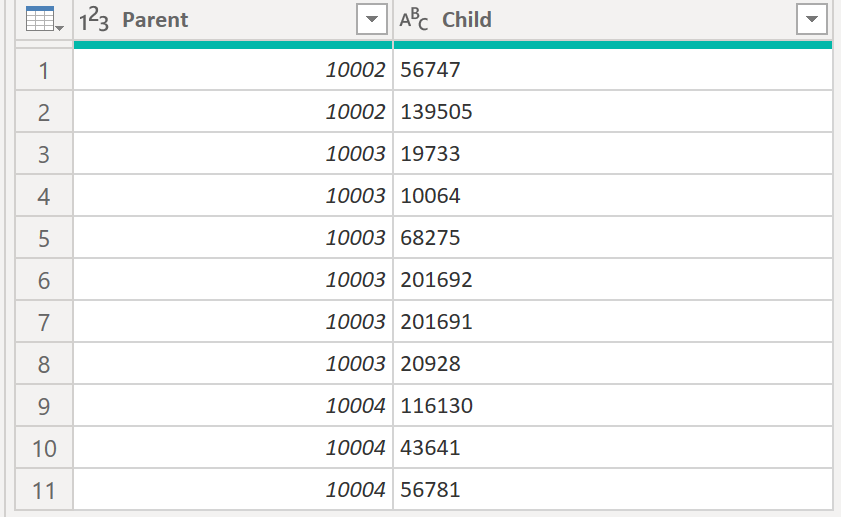
.
Add the following line of code:
#"Grouped Rows" = Table.Group(#"Changed Type", {"Parent"}, {"Child", each Text.Combine([Child], ","), type text}).
Result:
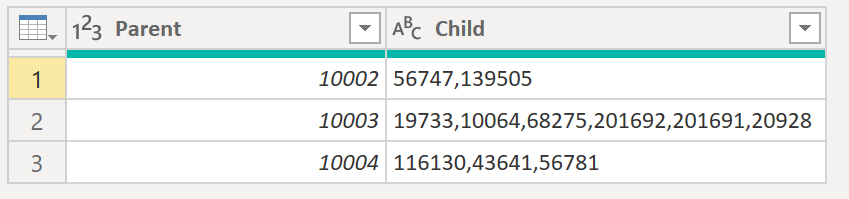
.
Here the full M code for Power Query:
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("Zc67DcAgDIThXVxTnB/YeBbE/msEGiIn7Sf9p5uTGIBQo+5hQau9wpod/ZIeylCtArgV8SFRKwF7yp/4Qynjip1tdlYUMnXjIvv32LIe", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [Parent = _t, Child = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"Parent", Int64.Type}, {"Child", type text}}),
#"Grouped Rows" = Table.Group(#"Changed Type", {"Parent"}, {"Child", each Text.Combine([Child], ","), type text})
in
#"Grouped Rows".
You could now even do a split by delimiter to transform the comma separated lists into columns:
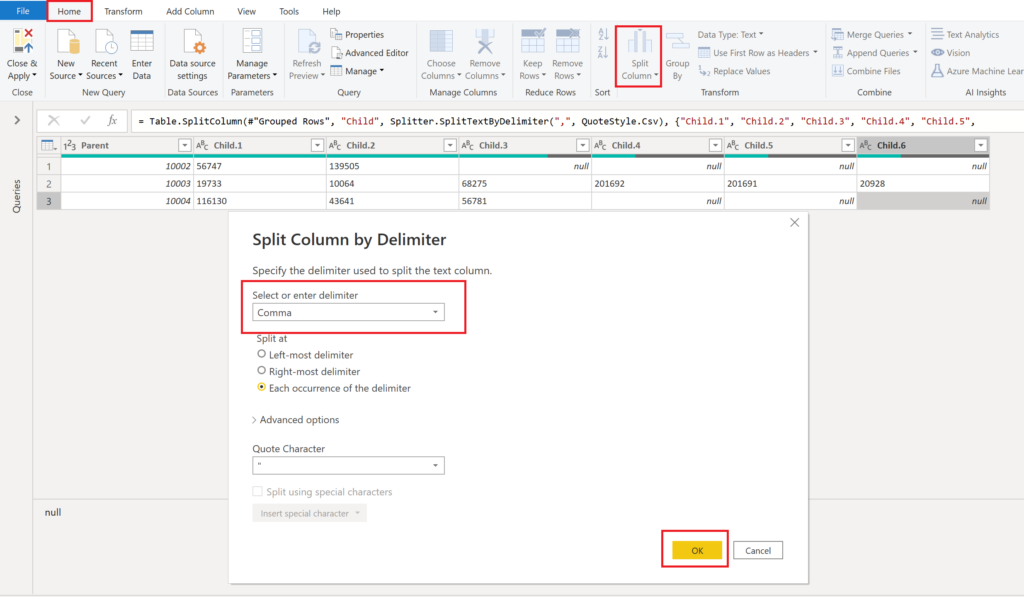
.
11. Calculate duration from “time” column
I have seen this already a couple of times in the Power BI community forum. Let’s say you have the following column in a table:
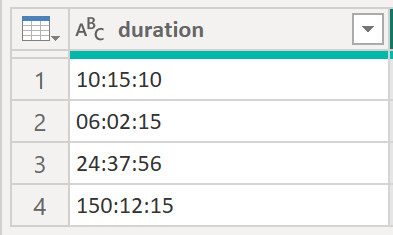
.
The column above is not providing you with a timestamp but instead with a duration in the format hhhh:mm:ss. In fact, the hour part could be a of a non fixed nature with a flexible number of digits. The problem is that Power BI does not know how to handle this type of data. And what does Power BI do, if it doesn’t know how to deal with a specific data type? Well, it converts it to text. This, in turn, means that we cannot use the column in any calculations. So, one way to circumvent this issue is to translate the text string into a number. I’d suggest to use the most granular one that you need in order to answer your analytical need. Most of the time this is seconds, though minutes could be enough in some cases as well. Either way, in this case we go for seconds.
.
Below the result:
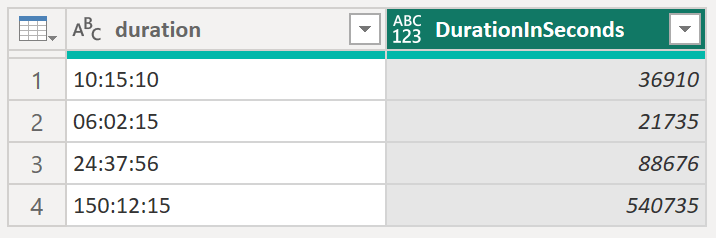
.
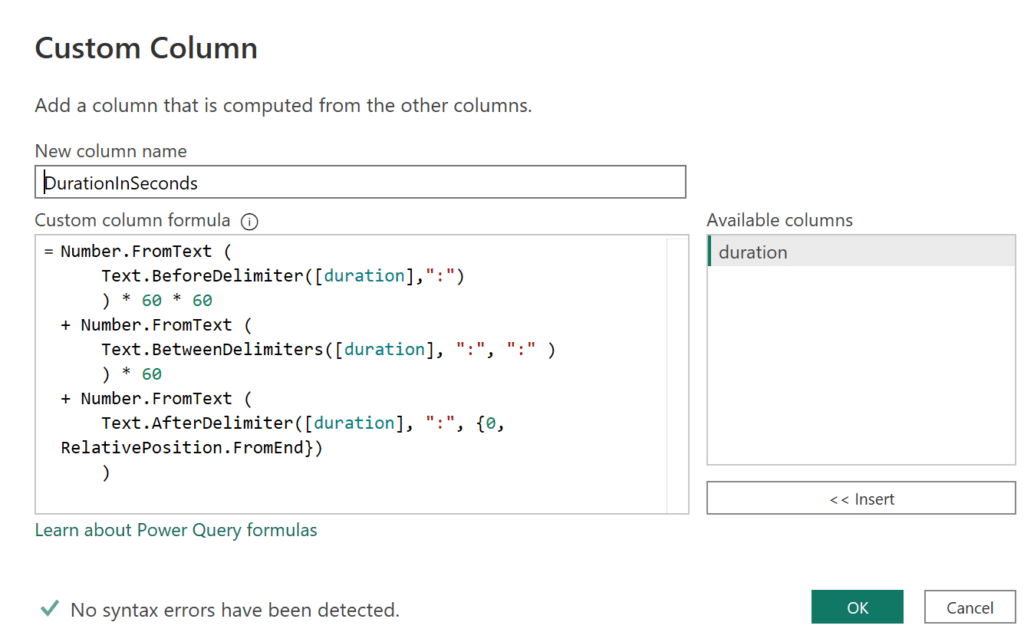
And here the code for the new column:
= Number.FromText (
Text.BeforeDelimiter([duration],":")
) * 60 * 60
+ Number.FromText (
Text.BetweenDelimiters([duration], ":", ":" )
) * 60
+ Number.FromText (
Text.AfterDelimiter([duration], ":", {0, RelativePosition.FromEnd})
)
.
Here the code in advanced editor:
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45WMjSwMjS1MjRQitWJVjIwszIwAvLBHCMTK2NzK1MzMMfQFKgOIhULAA==", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [duration = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"duration", type text}}),
#"Added Custom" = Table.AddColumn(#"Changed Type", "DurationInSeconds", each Number.FromText (
Text.BeforeDelimiter([duration],":")
) * 60 * 60
+ Number.FromText (
Text.BetweenDelimiters([duration], ":", ":" )
) * 60
+ Number.FromText (
Text.AfterDelimiter([duration], ":", {0, RelativePosition.FromEnd})
))
in
#"Added Custom".
There is also the option to convert the string column into the duration data type. Unfortunately, we need some more ifs and buts in the code, but here the result:
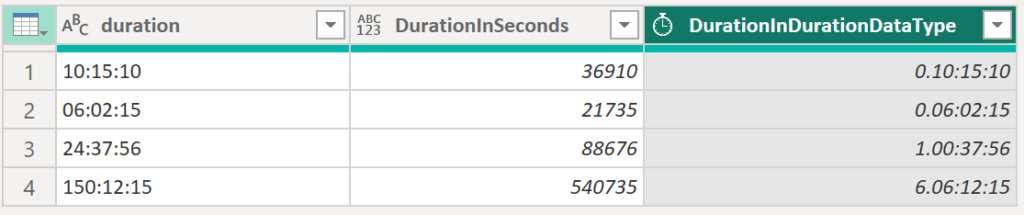
.
= Number.ToText (
if Number.FromText ( Text.BeforeDelimiter([duration],":") ) >= 24
then Number.RoundDown ( Number.FromText ( Text.BeforeDelimiter([duration],":") ) / 24 )
else 0 ) & "." &
( if Number.FromText ( Text.BeforeDelimiter([duration],":") ) >= 24
then Number.ToText ( Number.Mod (
Number.FromText ( Text.BeforeDelimiter([duration],":") ), 24 ) )
else Text.BeforeDelimiter([duration],":") ) & ":" &
Text.BetweenDelimiters([duration], ":", ":" ) & ":" &
Text.AfterDelimiter([duration], ":", {0, RelativePosition.FromEnd})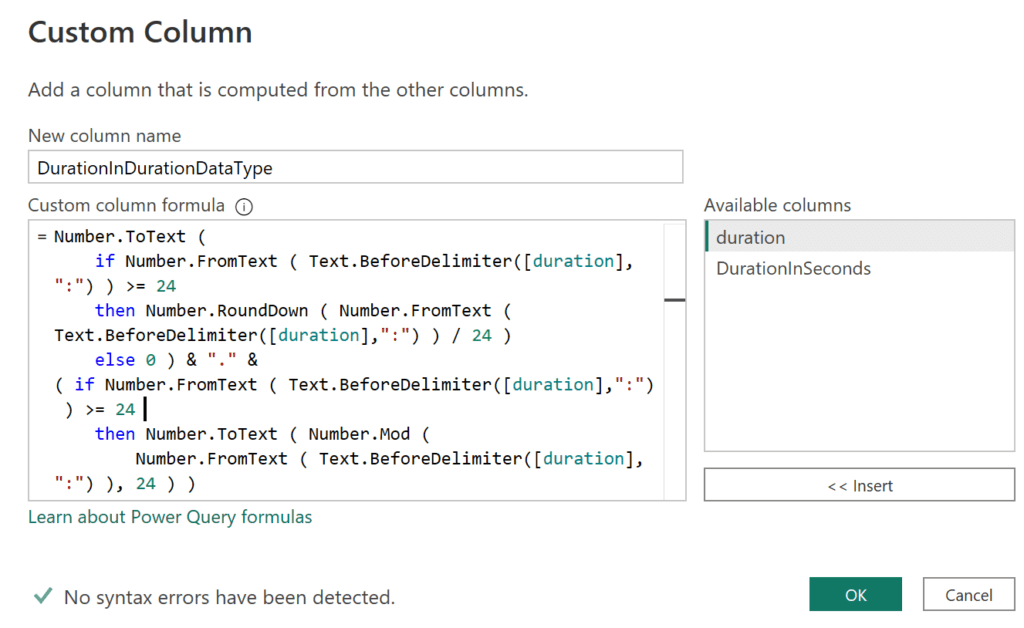
.
Here the code in advanced editor:
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45WMjSwMjS1MjRQitWJVjIwszIwAvLBHCMTK2NzK1MzMMfQFKgOIhULAA==", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [duration = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"duration", type text}}),
#"Added Custom" = Table.AddColumn(#"Changed Type", "DurationInSeconds", each Number.FromText (
Text.BeforeDelimiter([duration],":")
) * 60 * 60
+ Number.FromText (
Text.BetweenDelimiters([duration], ":", ":" )
) * 60
+ Number.FromText (
Text.AfterDelimiter([duration], ":", {0, RelativePosition.FromEnd})
)),
#"Added Custom1" = Table.AddColumn(#"Added Custom", "DurationInDurationDataType", each Number.ToText (
if Number.FromText ( Text.BeforeDelimiter([duration],":") ) >= 24
then Number.RoundDown ( Number.FromText ( Text.BeforeDelimiter([duration],":") ) / 24 )
else 0 ) & "." &
( if Number.FromText ( Text.BeforeDelimiter([duration],":") ) >= 24
then Number.ToText ( Number.Mod (
Number.FromText ( Text.BeforeDelimiter([duration],":") ), 24 ) )
else Text.BeforeDelimiter([duration],":") ) & ":" &
Text.BetweenDelimiters([duration], ":", ":" ) & ":" &
Text.AfterDelimiter([duration], ":", {0, RelativePosition.FromEnd})),
#"Changed Type1" = Table.TransformColumnTypes(#"Added Custom1",{{"DurationInDurationDataType", type duration}})
in
#"Changed Type1"