
how to use azure function and data factory for creating and managing partitions in azure sql database and power bi.

introduction.
This blog post is a continuation of the previous post, where we implemented an Azure Function to create and manage our own custom partitions on tables in Power BI semantic models. Now, we are going to use this function within an Azure Data Factory pipeline to demonstrate a practical use case for automated custom partitioning. We follow a mirroring approach where we first partition a table in the source, namely an Azure SQL Database. Subsequently, we want to create and match those exact same partitions on the respective table in the Power BI semantic model. Having mirroring partitions in place, we are able to tremendously slim our ETL flow refreshing only the parts of a table that we actually need to. Further, when Power BI asks for data from a specific partition, we ensure that the source is not scanning data from other parts of the table. This will decrease load time and thereby liberate capacities to refresh data more often. As mentioned before, the partition management activities are orchestrated by Azure Data Factory.
.
prerequisites.
1. A Power BI premium capacity or a PPU license. XMLA endpoints can only be used on premium workspaces.
2. A semantic model published to a premium workspace. The dataset shall contain a large table that is intended to be partitioned
3. The Azure Function created in the previous blog post
4. An Azure Data Factory
5. An Azure SQL Database which shall be the source for the semantic model
.
plan of action.
1. What is our starting point?
2. Fix access and settings in Azure SQL Database and Power BI
3. Create stored procedure for partitioning in Azure SQL Database
4. Build Azure Data Factory pipeline for orchestration
5. Showtime!
.
1. What is our starting point?
Let’s quickly recap the prerequisites.
A premium workspace in Power BI with a semantic model:
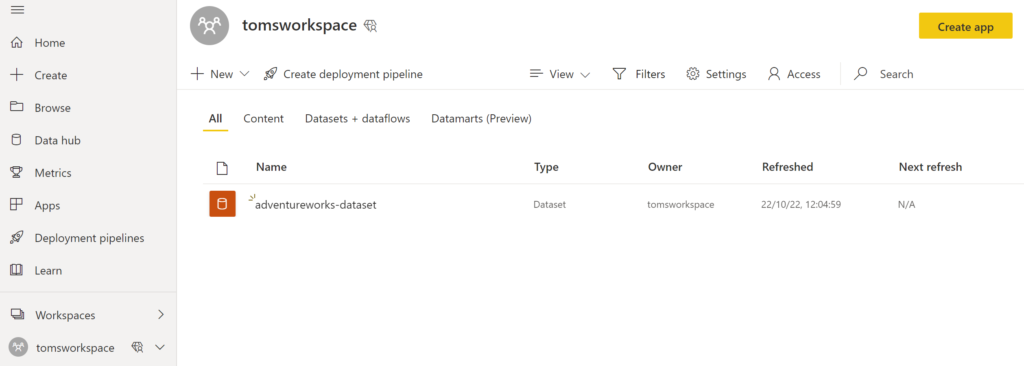
.
Our model looks like this:
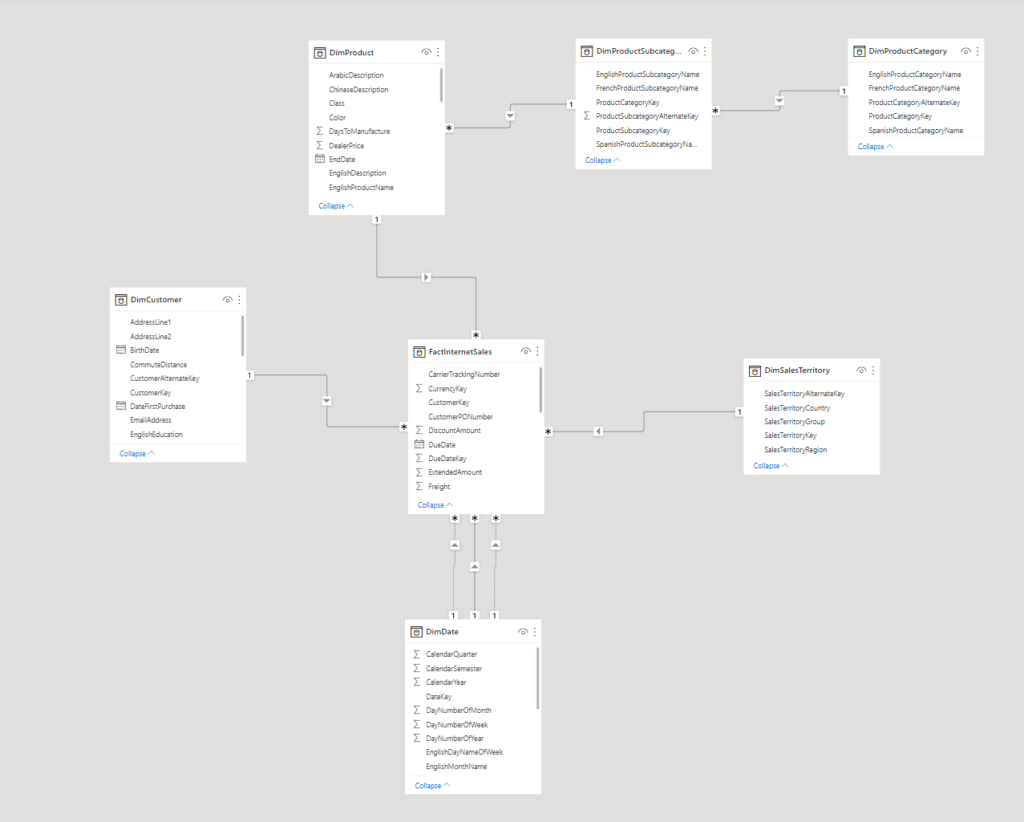
.
We are going to create partitions on the table FactInternetSales. In this sample, the table has only about 60 000 rows which, admittedly, is not large enough to make partitioning worth in real life.
.
And here all the Azure resources we need:
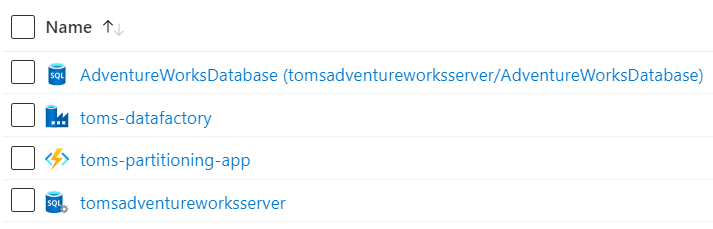
.
The toms-partitioning-app function will be doing the magic on the Power BI side (once again, see this blog post for reference), while we will be utilising a stored procedure and a config / meta table to partition the table in the AdventureWorks database. By the way, we are using the large AdventureWorks sample. Worth pointing out, this is not the lightweight version that is offered by Azure when creating an Azure SQL Database resource. If you would like to find out how to add the real AdventureWorks sample to an Azure SQL database, make sure to check out this blog post.
.
2. Fix access and settings in Azure SQL Database and Power BI
Add the data factory’s managed identity to the AdventureWorks Database by running the T-SQL statement below.
CREATE USER [toms-datafactory] FROM EXTERNAL PROVIDER; GO
.
Create a role with EXECUTE, SELECT and ALTER permissions and assign the role to the data factory. Note, we created the schema [meta] in advance. Both the config / meta partition table and the stored procedure are laying in that schema. The fact table, however, belongs to the [dbo] schema.
GRANT SELECT, EXECUTE ON SCHEMA:: [meta] TO [partitionmanager]; GO GRANT SELECT ON SCHEMA:: [dbo] TO [partitionmanager]; GO GRANT ALTER ON DATABASE:: [AdventureWorksDatabase] TO [partitionmanager]; GO EXECUTE sp_addrolemember 'partitionmanager', 'toms-datafactory'; GO
.
Next, we create a security group in Azure and add the function app as a member:
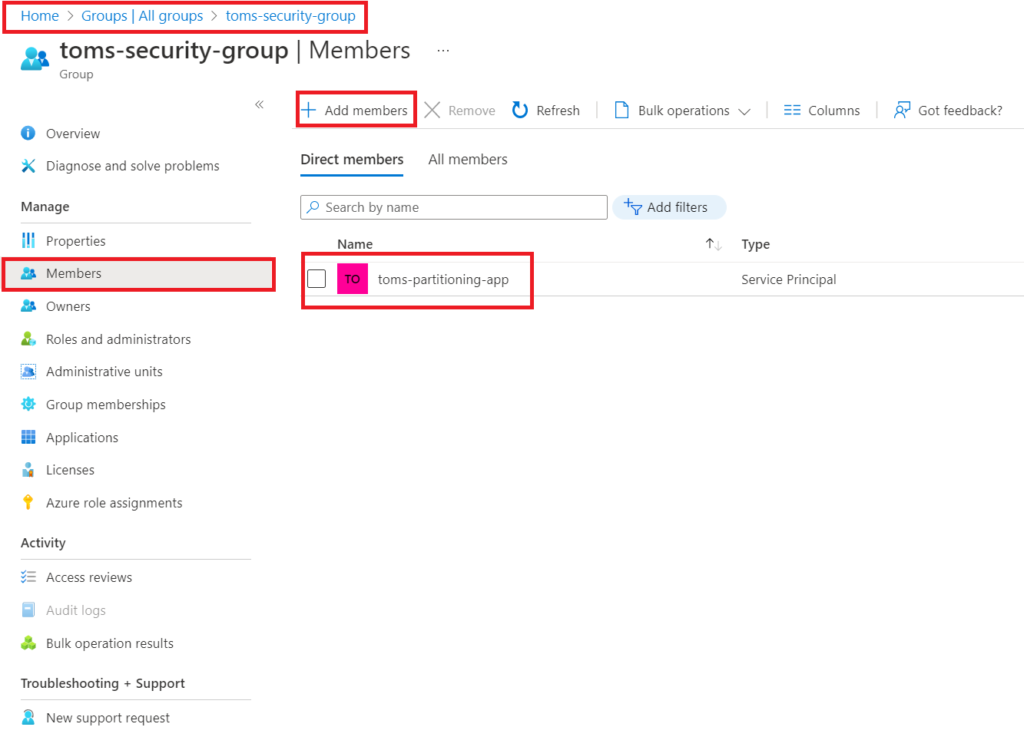
.
In the Admin portal, add that security group to the Admin API setting that allows service principals to use Power BI APIs.
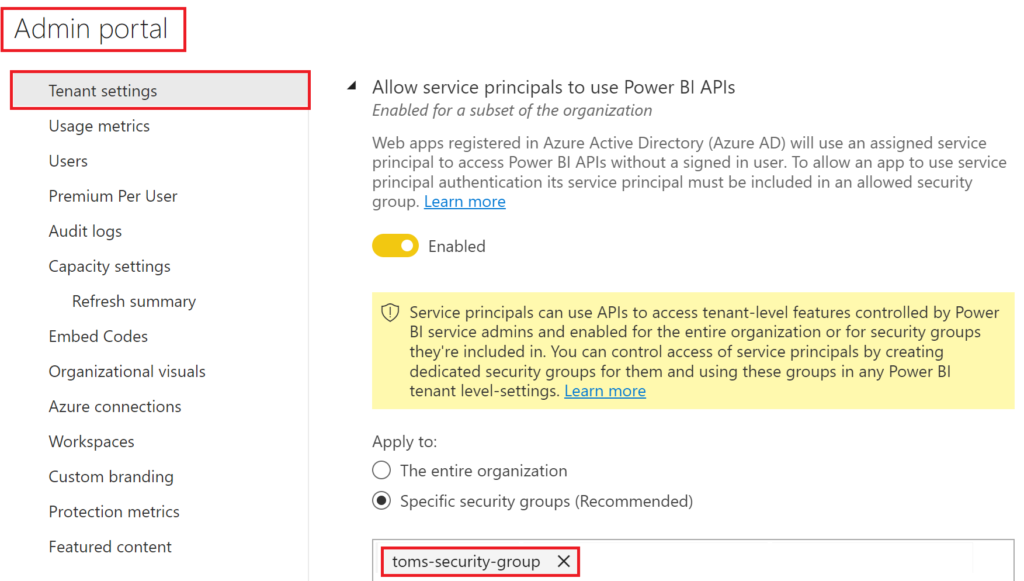
.
Then, go into Power BI and add the function to your workspace with the Member role.
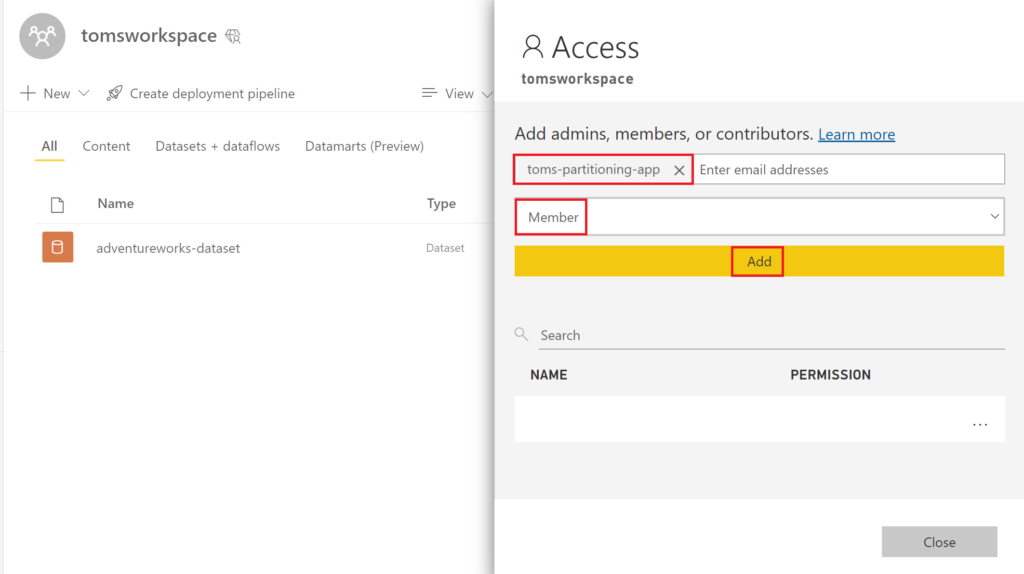
.
We need to tell Power BI to allow read/write on XMLA endpoints, too. For this, navigate to the Admin portal and click on Premium Per User (or Capacity settings depending on what kind of premium type you are using). Finally, pick Read Write in the XMLA Endpoint dropdown:
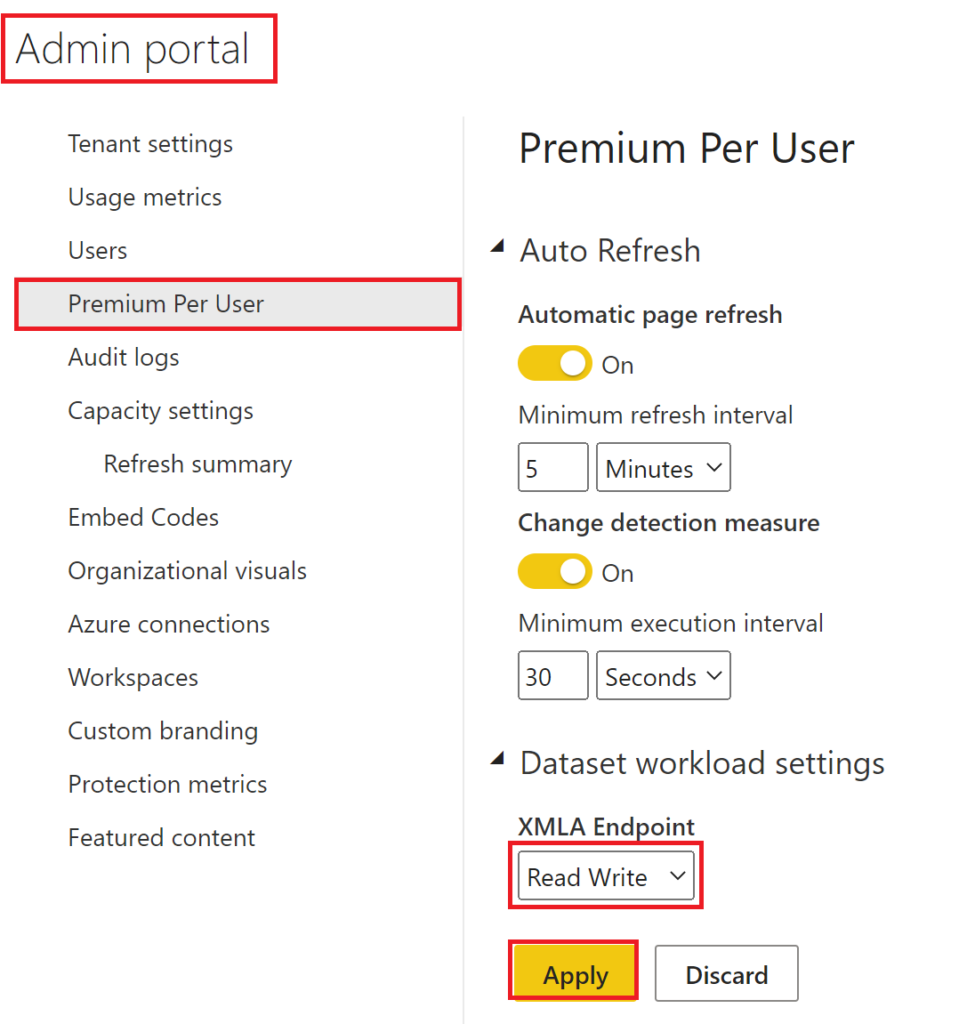
.
3. Create stored procedure for partitioning in Azure SQL Database
First off, this one is just a suggestion. You might have a totally different partition strategy, which is absolutely great! For example, some of you might not want to use dynamic boundaries for partitions while others do not appreciate a meta driven approach. In any case, if you use major parts of that stored procedure: Awesome! If you just snitch a couple of lines: Awesome again! Or if you just take out some inspiration and conclude that this stored procedure is crap: Once again, awesome!
We begin by creating a meta table that works as our configuration for the partitions. Note, I tried to make it as dynamic as possible where you should be able to add as many partitions as you want. Once again, it is a dynamic or rather a rolling window approach where each partition contains data for a specific time window. This means, the number of partitions will always stay the same and data moves through them while time passes. To illustrate this, we will not have one partition for the year 2011, another one for 2012, yet another one for 2013 etc. Instead, we are going for one partition that contains the last three months, another partition that covers the following six months, and a third partition that contains all data earlier than the other two partitions. This means, we need to run our partition management pipeline once a month. Then, the partition boundaries change whereby data is pushed to the next partition.
CREATE TABLE [meta].[TablePartition] ( [TablePartitionID] NVARCHAR(310) NOT NULL, [Schema] NVARCHAR(100) NOT NULL, [Table] NVARCHAR(250) NOT NULL, [Column] NVARCHAR(250) NOT NULL, [PartitionName] NVARCHAR(50) NOT NULL, [PartitionLength] INT NOT NULL, [PartitionOrder] INT NOT NULL ) GO
.
As an example. two partitions for the table FactInternetSales that we need to define in meta.TablePartition:
INSERT INTO [meta].[TablePartition] VALUES ( 'dbo.FactInternetSales | CurrentPeriod', 'dbo', 'FactInternetSales', 'OrderDateKey', 'CurrentPeriod', 3, 1 ) INSERT INTO [meta].[TablePartition] VALUES ( 'dbo.FactInternetSales | PreviousPeriod', 'dbo', 'FactInternetSales', 'OrderDateKey', 'PreviousPeriod', 6, 2 )
.

.
You might wonder what the attributes mean, especially PartitionName, PartitionLength and PartitionOrder. Let’s say, today is the 21st of November 2022 (20221120) and we run the stored procedure with the configuration of the meta table above. The procedure will set the boundaries for the partitions of the FactInternetSales table as follows:
– CurrentPeriod: WHERE [OrderDateKey] >= 20220801
– PreviousPeriod: WHERE [OrderDateKey] >= 20220201 AND [OrderDateKey] < 20220801
– Archive: WHERE [OrderDateKey] < 20220201
.
This means, the first partition for the table FactInternetSales (PartitionOrder = 1) called CurrentPeriod contains all rows with OrderDates that have happened during this month and three months back (PartitionLength = 3). The next partition (PartitionOrder = 2) with the name PreviousPeriod covers all Orders with an OrderDate laying in the subsequent six months (PartitionLength = 6). By default, the last partition is called Archive and contains the rest of the data meaning all Orders with OrderDate before the last specified partition (in our case PreviousPeriod). Note, we do not need to define the Archive partition in the meta table. Also, you may name your partitions as you wish.
.
In the following, the stored procedure that adds or changes the partitions for the tables specified in the config table above.
--------------------------------------------------------------------------------------------------------------
-- Stored Procedure to manage partitions. See full walk-through on https://www.tackytech.blog/
--------------------------------------------------------------------------------------------------------------
ALTER PROCEDURE [meta].[ManagePartition]
(
@partitionschema NVARCHAR(250),
@partitiontable NVARCHAR(250)
)
AS
BEGiN
DECLARE @sql as NVARCHAR(MAX);
DECLARE @rowcount as INT;
DECLARE @partitioncolumn as NVARCHAR(250);
DECLARE @partitionboundarytobe NVARCHAR(10);
DECLARE @partitionboundaryinplace NVARCHAR(10);
DECLARE @clusteredindex NVARCHAR (500);
DECLARE @partitionscheme NVARCHAR (250);
DECLARE @partitionfunction NVARCHAR (250);
DECLARE @datetime as DATETIME = GETDATE();
--------------------------------------------------------------------------------------------------------------
-- save tablepartition and its attributes (incl. boundary values) in #partitionTableTemp
--------------------------------------------------------------------------------------------------------------
DROP TABLE IF EXISTS #partitionTableTemp
SELECT
[PartitionOrder],
[Schema],
[Table],
[Column],
[PartitionName],
[PartitionLength],
CASE
WHEN [PartitionOrder] = 1 THEN CONVERT ( NCHAR(8), EOMONTH ( DATEADD ( MONTH, -[PartitionLength] - 1, @datetime ) ), 112 )
ELSE CONVERT ( NCHAR(8), EOMONTH ( DATEADD ( MONTH, - SUM([PartitionLength]) OVER ( ORDER BY [PartitionOrder] ) - 1, @datetime ) ), 112 )
END as BoundaryValue
INTO #partitionTableTemp
FROM meta.TablePartition
WHERE [Schema] = @partitionschema AND [Table] = @partitiontable
SELECT
@partitioncolumn = MAX ( [Column] )
FROM #partitionTableTemp;
--------------------------------------------------------------------------------------------------------------
-- check if index + partition scheme + partition function already exist on table
--------------------------------------------------------------------------------------------------------------
IF NOT EXISTS (
SELECT t.[name]
FROM sys.tables as t
INNER JOIN sys.schemas as s
ON t.[schema_id] = s.[schema_id]
INNER JOIN sys.indexes as i
ON t.[object_id] = i.[object_id]
AND i.[type] IN ( 0, 1 )
INNER JOIN sys.partition_schemes ps
ON i.[data_space_id] = ps.[data_space_id]
INNER JOIN sys.partition_functions pf
ON ps.function_id = pf.function_id
WHERE t.[name] = @partitiontable AND s.[name] = @partitionschema
)
--------------------------------------------------------------------------------------------------------------
-- either index or partition scheme or partition function do not exist --> (re)create them
--------------------------------------------------------------------------------------------------------------
BEGIN
--SELECT 'either index or partition scheme or partition function do not exist --> create partitions' as [message];
--------------------------------------------------------------------------------------------------------------
-- create partition function
--------------------------------------------------------------------------------------------------------------
SET @partitionfunction = 'PF_' + @partitiontable;
SET @sql =
' IF NOT EXISTS (
SELECT *
FROM sys.partition_functions
WHERE [Name] = ''' + @partitionfunction + '''
)
BEGIN
CREATE PARTITION FUNCTION ' + @partitionfunction + ' (INT) as RANGE LEFT
FOR VALUES ( '
SELECT
@rowcount = MAX ( [PartitionOrder] )
FROM #partitionTableTemp
WHILE @rowcount > 0
BEGIN
SELECT @partitionboundarytobe = BoundaryValue
FROM #partitionTableTemp
WHERE [PartitionOrder] = @rowcount
IF @rowcount > 1
SET @sql = @sql + @partitionboundarytobe + ', '
ELSE
SET @sql = @sql + @partitionboundarytobe + ') END'
SELECT @rowcount = @rowcount - 1
END
--SELECT 'create partition function if not exists' as [message], @sql as sqlstatement;
EXEC (@sql);
--------------------------------------------------------------------------------------------------------------
-- create partition scheme
--------------------------------------------------------------------------------------------------------------
SET @partitionscheme = 'PS_' + @partitiontable;
SET @sql =
' IF NOT EXISTS (
SELECT *
FROM sys.partition_schemes
WHERE [Name] = ''' + @partitionscheme + '''
)
BEGIN
CREATE PARTITION SCHEME ' + @partitionscheme + '
as PARTITION ' + @partitionfunction + '
ALL TO ([PRIMARY]);
END'
--SELECT 'create partition scheme if not exists' as [message], @sql as sqlstatement;
EXEC (@sql);
--------------------------------------------------------------------------------------------------------------
-- create partition by re(creating) index
--------------------------------------------------------------------------------------------------------------
SELECT
@clusteredindex = [name]
FROM sys.indexes
WHERE is_hypothetical = 0
AND index_id <> 0
AND [type_desc] = 'CLUSTERED'
AND [object_id] = OBJECT_ID ( @partitiontable )
IF @clusteredindex IS NOT NULL
BEGIN
SET @sql =
'DROP INDEX IF EXISTS '
+ @clusteredindex + ' ON ' + @partitionschema + '.' + @partitiontable
SELECT @sql
EXEC (@sql)
END
SET @sql =
'CREATE CLUSTERED INDEX CIX_' + @partitiontable + '_' + @partitioncolumn + ' ON [' + @partitionschema + '].[' + @partitiontable + ']
( [' + @partitioncolumn + '] ) WITH ( STATISTICS_NORECOMPUTE = OFF, DROP_EXISTING = OFF, ONLINE = OFF )
ON ' + @partitionscheme + ' ( [' + @partitioncolumn + '] );'
--SELECT 'create partitions by (re)creating index' as [message], @sql as sqlstatement;
EXEC (@sql)
--SELECT 'partitions succesfully created' as [message];
END
--------------------------------------------------------------------------------------------------------------
-- partition function + partition scheme + index already exist on table
--------------------------------------------------------------------------------------------------------------
ELSE BEGIN
--SELECT 'partitions already exist' as [message];
--------------------------------------------------------------------------------------------------------------
-- save boundary values "in place" and boundary values "to be" in #alterPartitionTableTemp
--------------------------------------------------------------------------------------------------------------
DROP TABLE IF EXISTS #alterPartitionTableTemp;
;WITH cte as
(
SELECT
ROW_NUMBER () OVER ( ORDER BY prv.[Value] DESC ) as [PartitionOrderInPlace],
CAST ( prv.[Value] as NVARCHAR ) as [PartitionBoundaryValueInPlace],
pf.[name] as [PartitionFunction],
ps.[name] as [PartitionScheme]
FROM sys.tables as t
INNER JOIN sys.schemas as s
ON t.[schema_id] = s.[schema_id]
INNER JOIN sys.indexes as i
ON t.[object_id] = i.[object_id]
AND i.[type] IN ( 0, 1 )
INNER JOIN sys.partition_schemes ps
ON i.[data_space_id] = ps.[data_space_id]
INNER JOIN sys.partition_functions pf
ON ps.function_id = pf.function_id
INNER JOIN sys.partition_range_values prv
ON pf.function_id = prv.function_id
WHERE s.[name] = @partitionschema AND t.[name] = @partitiontable
)
SELECT
ROW_NUMBER () OVER ( ORDER BY ptt.[PartitionOrder] DESC ) as [rowcount],
ptt.[PartitionOrder] as PartitionOrderToBe,
ptt.[BoundaryValue] as PartitionBoundaryValueToBe,
cte.[PartitionOrderInPlace],
cte.[PartitionBoundaryValueInPlace],
cte.[PartitionFunction] as [PartitionFunction],
cte.[PartitionScheme] as [PartitionScheme]
INTO #alterPartitionTableTemp
FROM cte
FULL OUTER JOIN #partitionTableTemp ptt
ON cte.[PartitionOrderInPlace] = ptt.[PartitionOrder]
--------------------------------------------------------------------------------------------------------------
-- check if any partition boundary needs to be updated on existing partitions
--------------------------------------------------------------------------------------------------------------
IF EXISTS (
SELECT *
FROM #alterPartitionTableTemp
WHERE ( PartitionBoundaryValueToBe <> PartitionBoundaryValueInPlace ) OR
( [PartitionOrderToBe] IS NULL ) OR
( [PartitionOrderInPlace] IS NULL )
)
--------------------------------------------------------------------------------------------------------------
-- Partition boundaries need to be updated
--------------------------------------------------------------------------------------------------------------
BEGIN
--SELECT 'at least one boundary needs to be aligned --> alter partitions' as [message];
--------------------------------------------------------------------------------------------------------------
-- loop over partitions in #alterPartitionTableTemp to split and merge partitions
--------------------------------------------------------------------------------------------------------------
SELECT
@rowcount = MAX ( [rowcount] ),
@partitionfunction = MAX ( [PartitionFunction] ),
@partitionscheme = MAX ( [PartitionScheme] )
FROM #alterPartitionTableTemp
WHILE @rowcount > 0
BEGIN
SELECT
@partitionboundarytobe = [PartitionBoundaryValueToBe],
@partitionboundaryinplace = [PartitionBoundaryValueInPlace]
FROM #alterPartitionTableTemp
WHERE [rowcount] = @rowcount
IF @partitionboundarytobe <> @partitionboundaryinplace OR @partitionboundaryinplace IS NULL
BEGIN
SET @sql =
'ALTER PARTITION SCHEME ' + @partitionscheme + '
NEXT USED [PRIMARY];
IF NOT EXISTS (
SELECT *
FROM #alterPartitionTableTemp
WHERE [PartitionBoundaryValueInPlace] = '+ @partitionboundarytobe + ' )
BEGIN
ALTER PARTITION FUNCTION ' + @partitionfunction + ' ()
SPLIT RANGE (' + @partitionboundarytobe + ');
END'
--SELECT 'split partition on ' + @partitionboundarytobe as [message], @sql as sqlstatement;
EXEC (@sql);
END
IF @partitionboundarytobe <> @partitionboundaryinplace OR @partitionboundarytobe IS NULL
BEGIN
SET @sql =
'ALTER PARTITION SCHEME ' + @partitionscheme + '
NEXT USED [PRIMARY];
IF NOT EXISTS (
SELECT *
FROM #alterPartitionTableTemp
WHERE [PartitionBoundaryValueToBe] = ' + @partitionboundaryinplace + ' )
BEGIN
ALTER PARTITION FUNCTION ' + @partitionfunction + ' ()
MERGE RANGE (' + @partitionboundaryinplace + ');
END'
--SELECT 'merge partition on ' + @partitionboundaryinplace as [message], @sql as sqlstatement;
EXEC (@sql);
END
SET @rowcount = @rowcount - 1;
END
--SELECT 'partitions successully altered' [message];
END
--------------------------------------------------------------------------------------------------------------
-- no partition boundaries need to be updated
--------------------------------------------------------------------------------------------------------------
--ELSE BEGIN
--SELECT 'no boundary needs to be aligned --> no changes to partitions needed' as [message];
--END
END
--------------------------------------------------------------------------------------------------------------
-- return table with meta information for Azure Function
--------------------------------------------------------------------------------------------------------------
IF EXISTS ( SELECT * FROM #partitionTableTemp )
BEGIN
;WITH cte as
(
SELECT
[PartitionOrder],
[Table],
[PartitionName],
'[' + [Schema] + '].[' + [Table] + ']' as [SourceObject],
'[' + [Column] + ']' as [Column],
[BoundaryValue]
FROM #partitionTableTemp
UNION
SELECT
999999 as [PartitionOrder],
@partitiontable as [Table],
'Archive' as [PartitionName],
'[' + @partitionschema + '].[' + @partitiontable + ']' as [SourceObject],
'[' + @partitioncolumn + ']' as [Column],
NULL as [BoundaryValue]
)
SELECT
ROW_NUMBER() OVER ( ORDER BY [PartitionOrder] ASC ) as n,
[Table] as [table],
[PartitionName] as [partition],
[SourceObject] as [sourceobject],
CASE
WHEN [PartitionOrder] = 1 THEN [Column] + ' > ' + [BoundaryValue]
WHEN [PartitionOrder] = 999999 THEN [Column] + ' <= ' + LAG ([BoundaryValue]) OVER ( ORDER BY [PartitionOrder] ASC )
ELSE [Column] + ' > ' + [BoundaryValue] + ' AND ' + [Column] + ' <= ' + LAG ([BoundaryValue]) OVER ( ORDER BY [PartitionOrder] ASC )
END as [partitionstatement]
FROM cte
END
ELSE BEGIN
SELECT 'Note: To be partitioned table could not be found in meta.TablePartition' as [message]
END
END
.
Note, the partitioning is done on a clustered index. Further, there are a few commented select statements that can be useful during debugging. The stored procedure shall not only execute the partitioning on the tables in the database, but also provide crucial information for the body of the Azure function. Data factory is supposed to read and forward the output of the stored procedure into the body of the Azure function call. Unfortunately, data factory is not very good in reading several output semantic models from a stored procedure, which is why we skip the helpful debug messages and instead solely display the output table utilised in the body of the function call.
.
4. Build Azure Data Factory pipeline for orchestration
At first, we need to add a linked service for both Azure SQL Database and Azure Function. Note, the Azure SQL Database is a Data Store linked service while the Azure function falls under the Compute category.
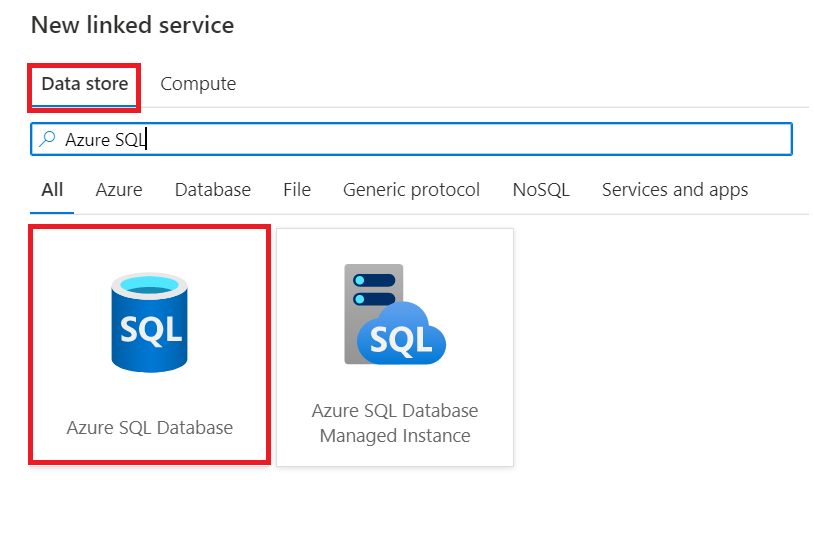
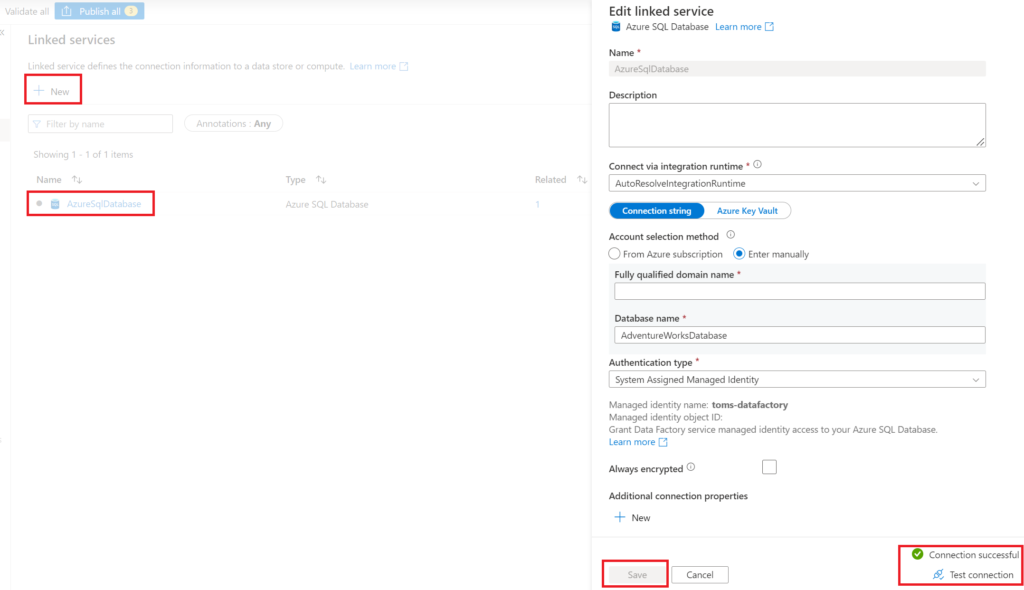
.
Navigate to Linked services under the Manage tab, click + New and search for Azure SQL Database. Then, fill in the information needed and test and save the connection. Here, we call the connection AzureSQLDatabase. Also, for the Azure Function, do the respective steps as seen below. Worth mentioning, you find the Function Key in the Azure resource under Functions > App keys.
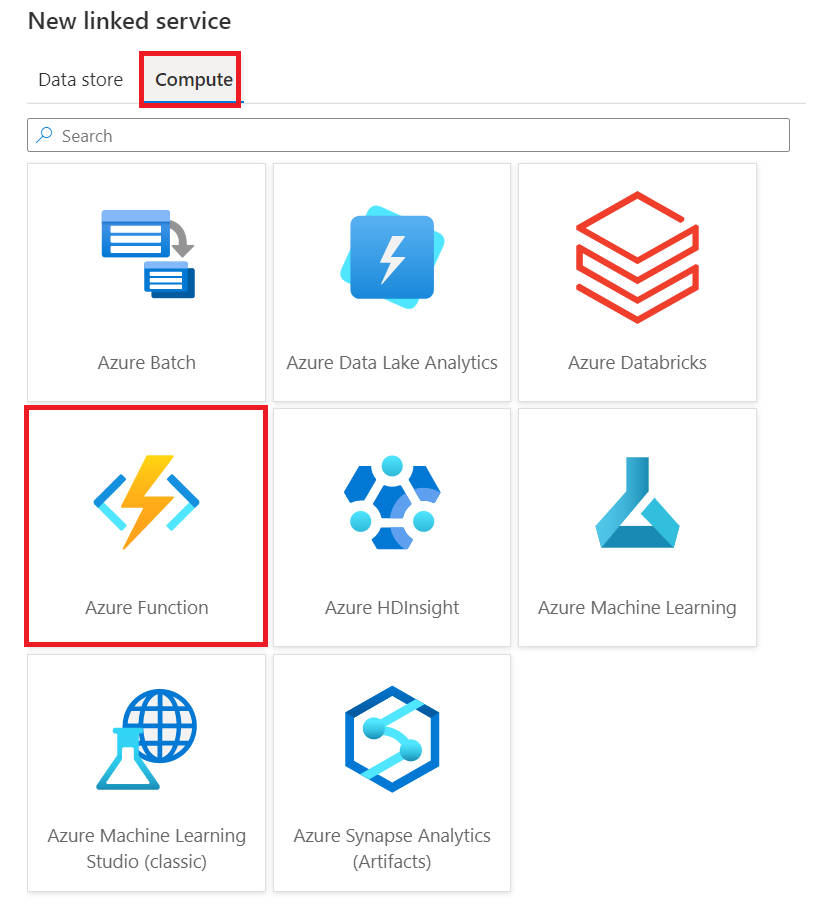
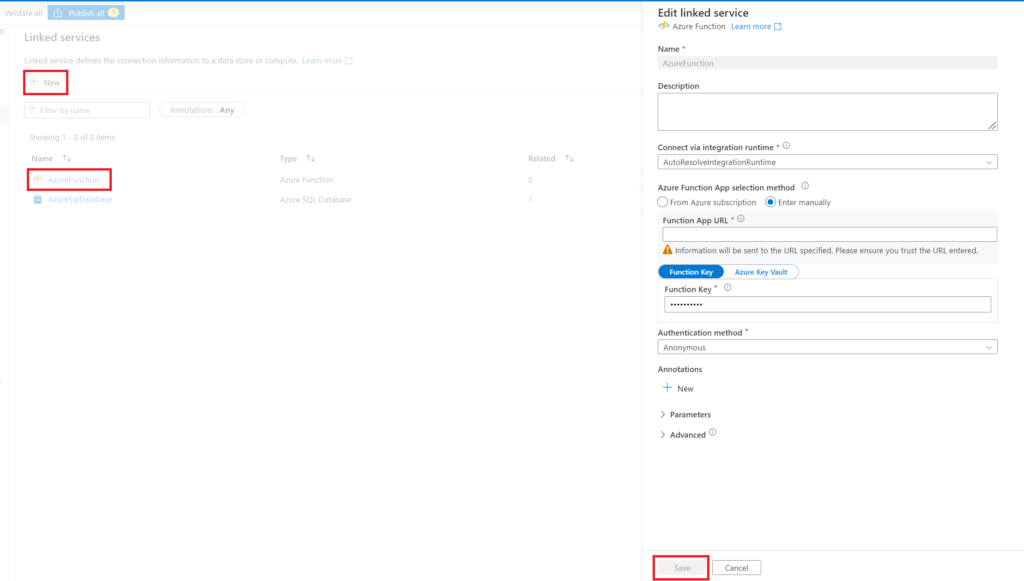
.
The next step is to add an Azure SQL Database dataset, by going back to the Author tab. Create one as shown in the picture below.
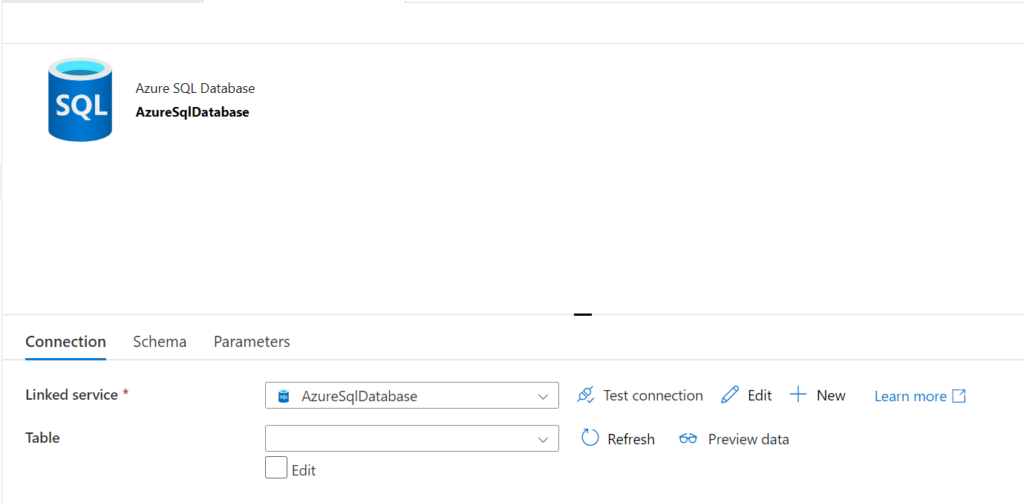
.
After, we create a new pipeline (toms_partitioning_pipeline) and add the parameters partitionSchema and partitionTable.
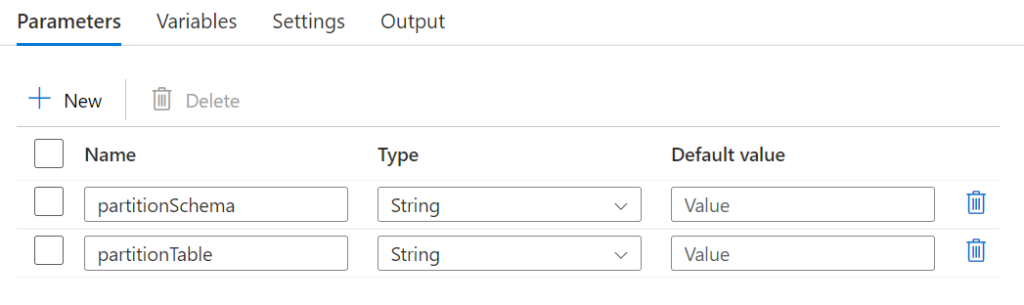
.
Then, we drag a Lookup activity into the pipeline which we name execute sp managepartition with the subsequent Settings. Note, the First row only box is unticked. Moreover, the parameters for the stored procedure come directly from the pipeline’s parameters.
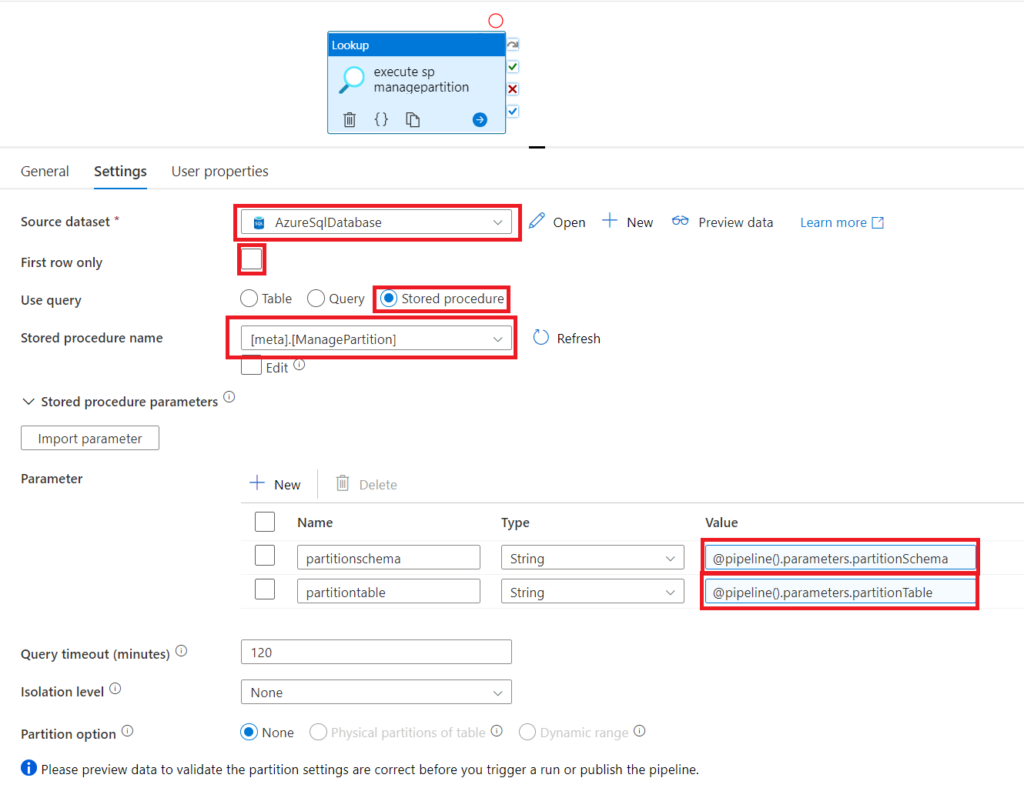
.
Now, we add a ForEach activity. Note, Power BI can have troubles when trying to change partitions for a table simultaneously. Hence, I recommend running the ForEach loop sequentially.
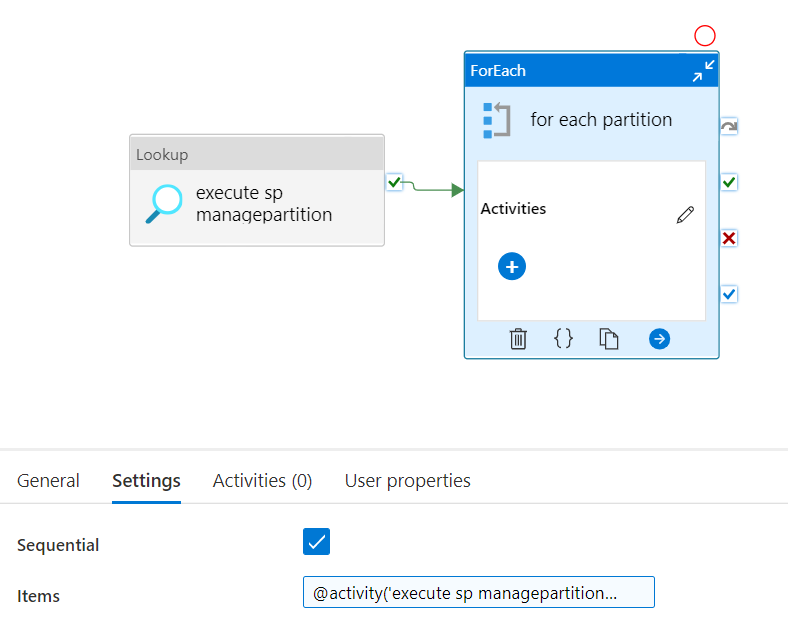
.
Items:
@activity('execute sp managepartition').output.value
.
Not much left! We pick an Azure Function activity, pull it into the ForEach loop and align the Settings as follows:
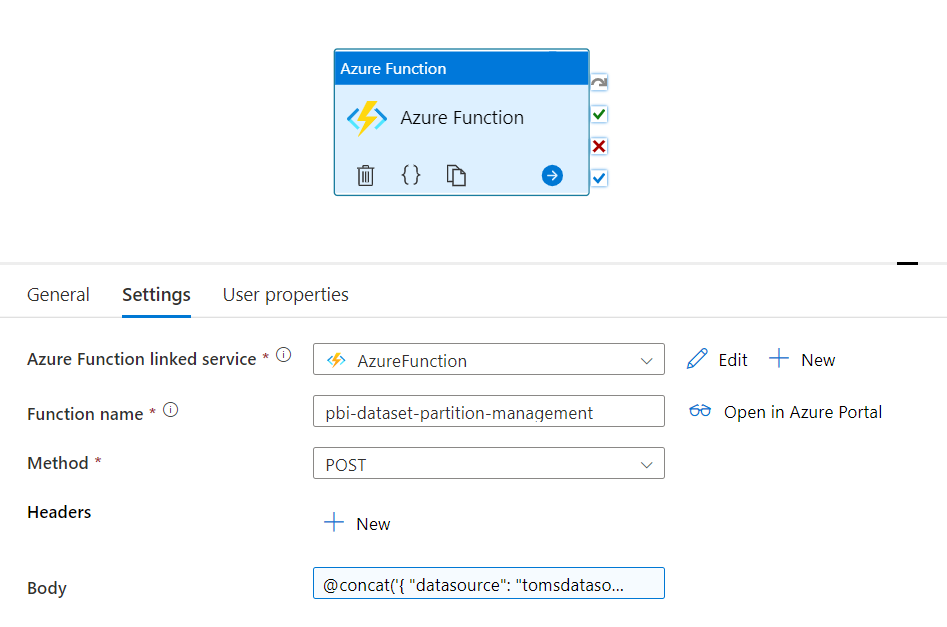
.
Body:
@concat ('{
"datasource": "tomsdatasource",
"connectionstring": "Data Source=toms[...].database.windows.net;Initial Catalog=AdventureWorksDatabase;Encrypt=true",
"workspace": "tomsworkspace",
"dataset": "adventureworks-dataset",
"table": "', item().table, '",
"partition": "', item().partition, '",
"sourceobject": "', item().sourceobject, '",
"partitionstatement": "', item().partitionstatement, '"
}')
Note, you might want to consider to even parameterise the other inputs, like workspace or dataset.
.
5. Showtime!
Before we run the pipeline, let’s check how our tatble looks like in the database and in Power BI. In SSMS, we run the query below to investigate the partition on the table FactInternetSales.
SELECT t.name as [table], s.name as [schema], i.[name] as [index], ps.[name] as [partition_scheme], pf.[name] as [partition_function], prv.[value] as [partitionboundary] FROM sys.tables as t INNER JOIN sys.schemas as s ON t.[schema_id] = s.[schema_id] LEFT OUTER JOIN sys.indexes as i ON t.[object_id] = i.[object_id] AND i.[type] IN ( 0, 1 ) LEFT OUTER JOIN sys.partition_schemes ps ON i.[data_space_id] = ps.[data_space_id] LEFT OUTER JOIN sys.partition_functions pf ON ps.function_id = pf.function_id LEFT OUTER JOIN sys.partition_range_values prv ON pf.function_id = prv.function_id WHERE t.[name] = 'FactInternetSales'
.
As expected, no partitions are in place, yet:

.
We stay in SSMS and check how the FactInternetSales table behaves in Power BI. Here, there are no surprises either: All rows are laying in one partition. Note, the partition name was manually changed so the Azure Function works properly.
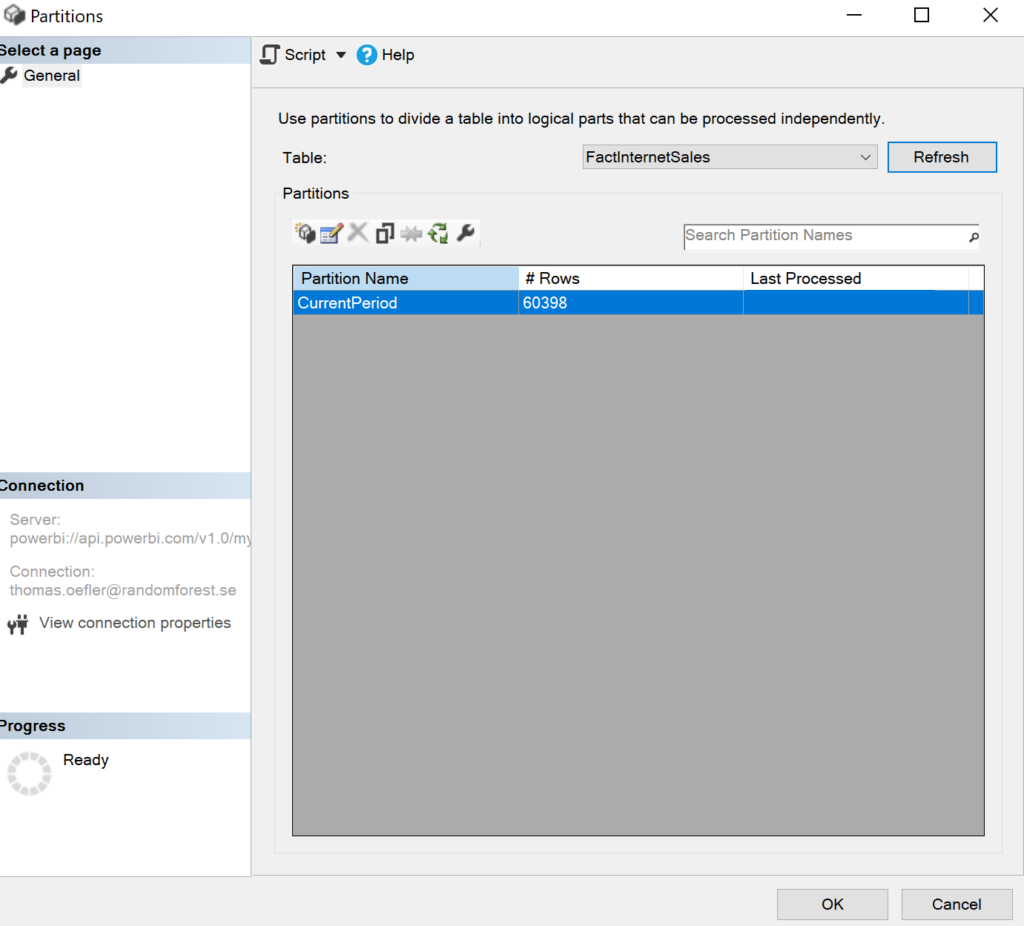
.
Finally, it’s time to run that thing! All you need to do is to fill in the schema and table name, because everything else is already defined in the meta/config table. The rest do the stored procedure and the function. So, let’s push that button!
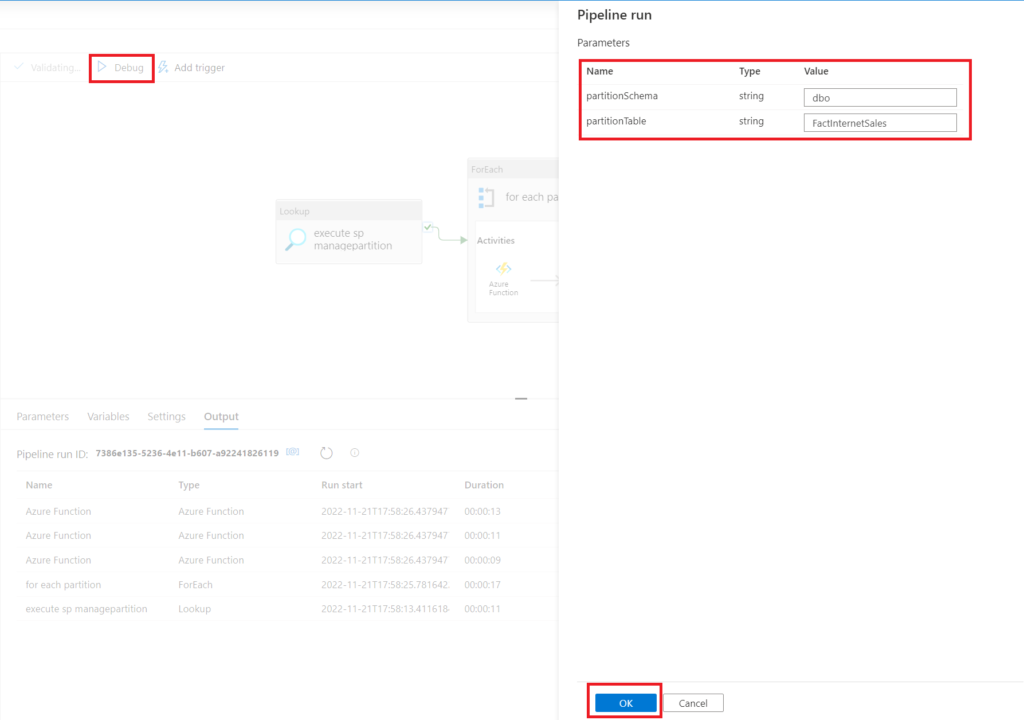
.
Green checkmarks :) The pipeline seemed to have worked!
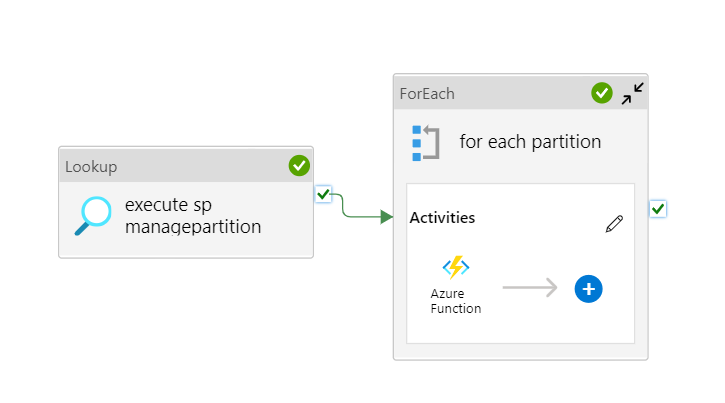
.
But what has exactly changed on the table? Let’s check the FactInternetSales table both in the database and in Power BI:


.
When refreshing the partitions in Power BI and comparing them to the data in the database, we can see that all rows are laying in the Archive partition:


.
This is because the AdventureWorks sample data is very old (OrderDate on FactInternetSales is between 2010 and 2014). So, let’s run our data factory pipeline once more to see whether changing partitions works as well as creating them! To not make this blog post even longer, I simply changed the stored procedure to use today’s date minus ten years. Here the results:



.
Here we go! Now, one can clearly see the advantage of the mirroring approach. Since the partitions in the source and in Power BI are exactly equivalent, we are able to simply refresh only the partitions that we are interested in. This is a big step to a slimmer and probably much quicker ETL flow.
.
end.
All that is left now is to specify your tables and partitions in the meta table. Generally, with a meta-driven approach, you can easily scale and alter configurations without making the slightest code change. Wanna add new tables? Wanna add new partitions to a table? Wanna change partition length? Just update the data in the meta table and run the pipeline! Lastly, with the parameters in the data factory pipeline, you can further customise your partition management strategy. Just create some triggers in a way that fits your schedule (i.e. every first Sunday per month). The next natural step would be to use the partitions when refreshing your Power BI semantic models, i.e. from Azure Data Factory.