
how to refresh individual tables or partitions in power bi semantic models (former datasets) with data factory.

introduction.
In the previous two blog posts we created an Azure function for managing custom partitions in Power BI semantic models and we created an Azure Data Factory pipeline automating the partition management for tables in both Azure SQL Database and Power BI. The second blog post utilised the Azure function from the first. This is because the best partition design in Power BI will not be of any help, if the data source still needs to scan the whole table to provide the fraction of the data that Power BI asks for. Hence, the second blog post creates partitions in the data source (that is an Azure SQL Database) matching the partitions in the target (Power BI). Now, it’s time to refresh the table partitions in the Power BI semantic model from an Azure Data Factory pipeline. You can use this blog post for refreshing individual tables as well. We will be using the enhanced refresh API for the table and partition processing. If you are on the look out to do the same but with Fabric data pipelines, make sure to check out this blog post.
.
prerequisites.
1. A semantic model published to a premium workspace (Premium per User or Premium)
2. An Azure Data Factory
3. Permission for the Azure Data Factory to call the refreshes REST API on the Power BI semantic model via managed identity. We followed the approach as described here.
.
plan of action.
1. What is our starting point?
2. Build Azure Data Factory pipeline
3. Showtime!
.
1. What is our starting point?
Let’s quickly recap the prerequisites.
A premium workspace in Power BI with a semantic model:
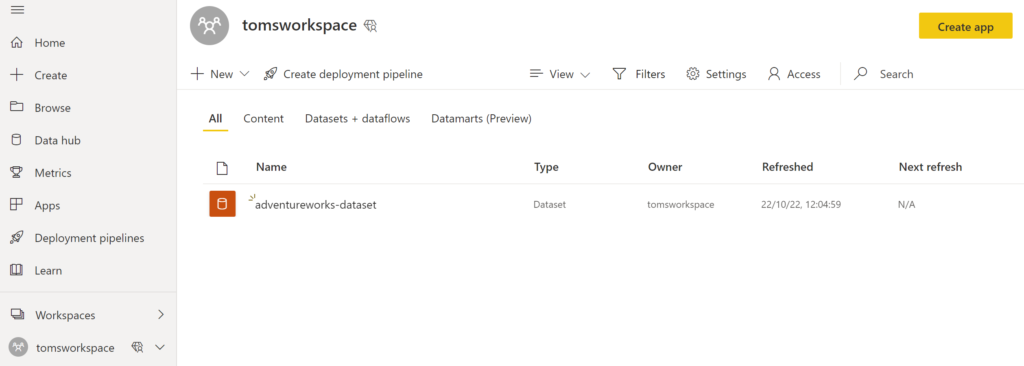
.
For the Power BI semantic model, we are using the large AdventureWorks sample and not the lightweight version that is offered by Azure when creating an Azure SQL Database. If you would like to find out how to add the real AdventureWorks sample to an Azure SQL database, make sure to check out this blog post.
Also, we gave Azure Data Factory the permission to call the REST API on the semantic model via managed identity. A detailed walk-through can be found in the blog post how to refresh power bi semantic models from data factory with managed identity.
.
2. Build Azure Data Factory pipeline
Here the settings and configurations for the web activity that performs the API call:
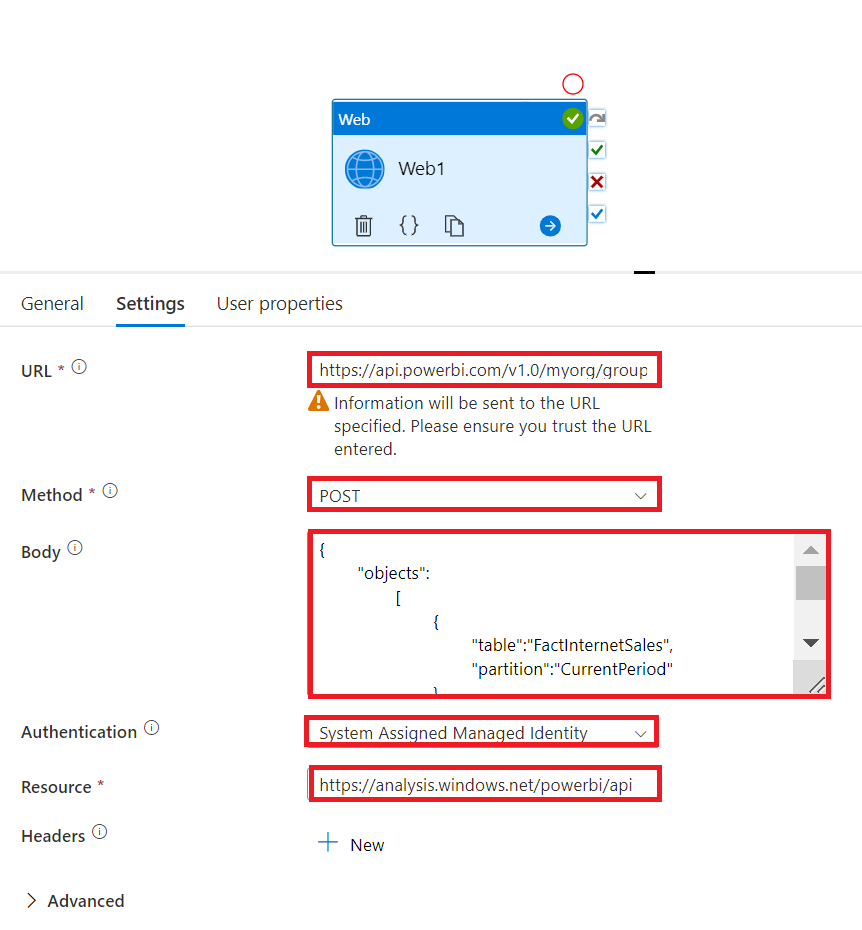
.
The URL follows this pattern:
https://api.powerbi.com/v1.0/myorg/groups/[workspaceID]/datasets/[datasetID]/refreshes
Both the workspaceID and the datasetID can be copied from the address / URL bar by clicking onto the semantic model in Power BI Service. See below.
The Method is Post
Paste the following into the Body:
{
"objects":
[
{
"table":"FactInternetSales",
"partition":"CurrentPeriod"
},
{
"table":"FactInternetSales",
"partition":"PreviousPeriod"
},
{
"table":"DimProduct"
}
]
}
.
Pick System Assigned Managed Identity (Legacy: Managed Identity) as Authentication. I once again refer to the managed identity blog post where we set up the prerequisites to be able to use data factory’s own managed identity.
Lastly, set Resource to
https://analysis.windows.net/powerbi/api
To retrieve the correct workspaceID and datasetID for the URL, navigate to the Power BI workspace and click on the semantic model:
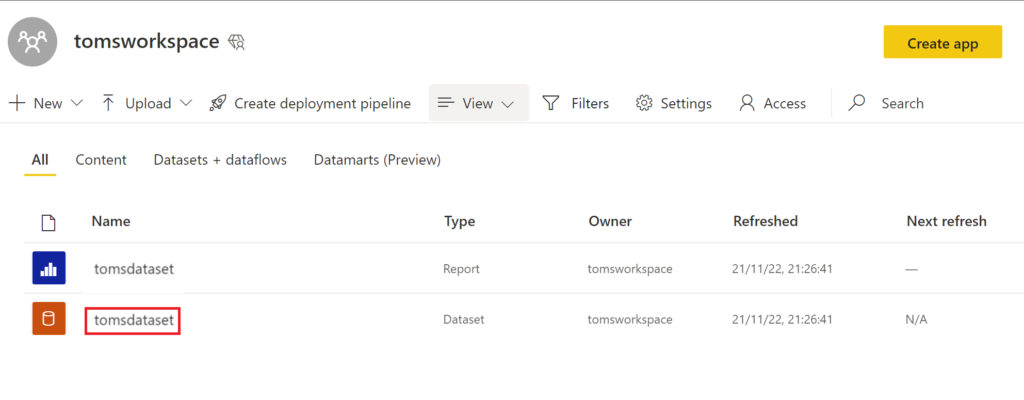
.
In the URL bar, you can now find the workspaceID between “groups/” and “/datasets” (first box: red) and the datasetID between “datasets/” and “/details” (second box: purple):
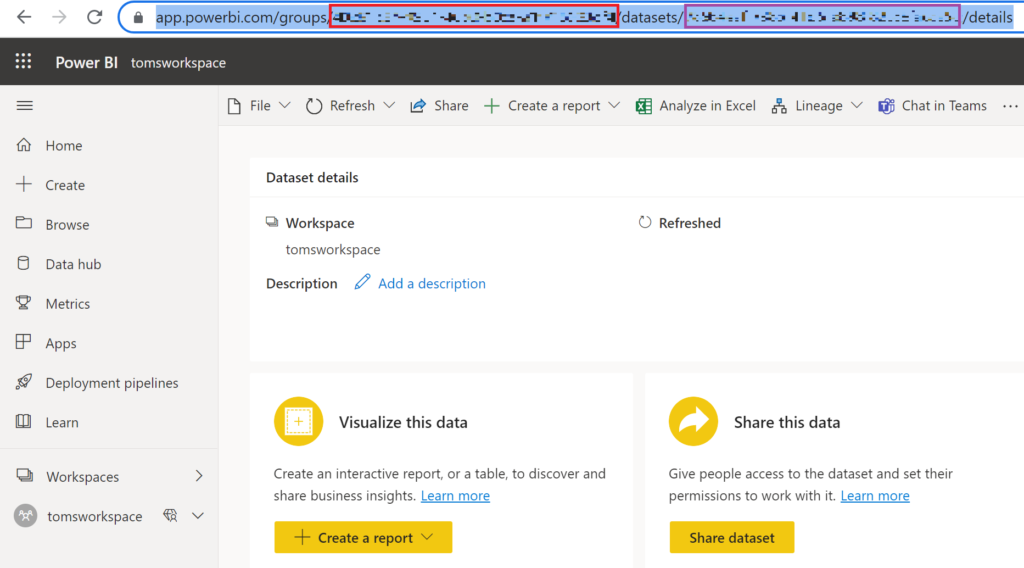
.
3. Showtime!
Let’s go and press that debug button!
.
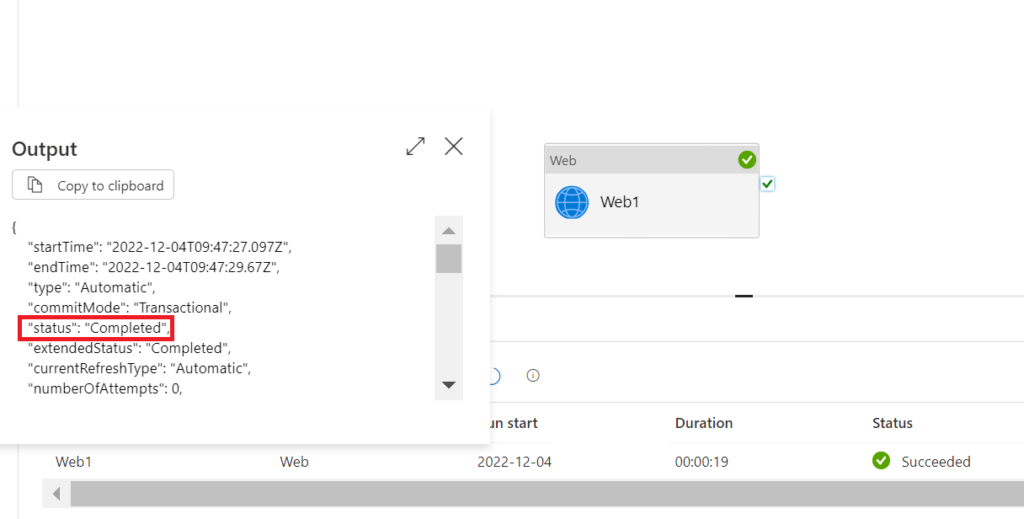
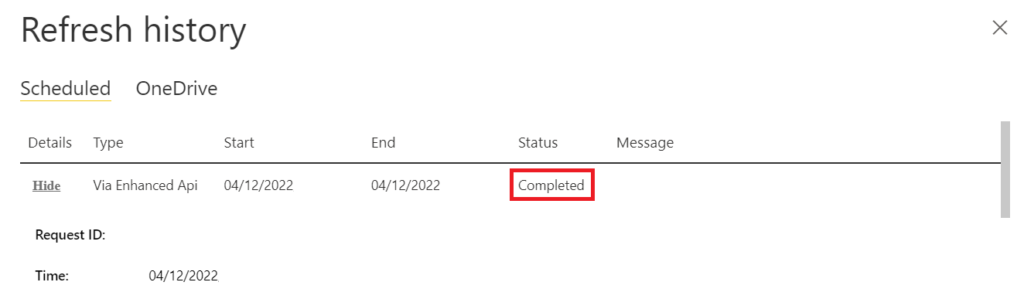
Nothing to be really surprised about, right? In refresh history in the Power BI Service, the call has also succeeded:
.
Well, for me there was actually a surprise: The “enhanced refresh” API call itself appeared to be synchronous, although according to Microsoft’s documentation it should be asynchronous (after all the “enhanced refresh” was called “asynchronous refresh” initially). Just a quick explanation on this. In our context, synchronous would mean that the calling client (data factory) keeps a connection until the refresh in Power BI has been completed (failed or succeeded). An asynchronous call, on the other hand, would just trigger a refresh and return an ID that you can use to ask for the refresh status afterwards. While the asynchronous call, at first sight, might sound like a bit of a hassle (recurring queries on the refresh status requires additional development effort), it does provide more flexibility for enterprise solutions. But how did we get to the conclusion that the call above was synchronous-like? Well, it is the output which tells us the refresh has successfully been completed. An asynchronous call, however, would not return such information and instead have the response as per below:
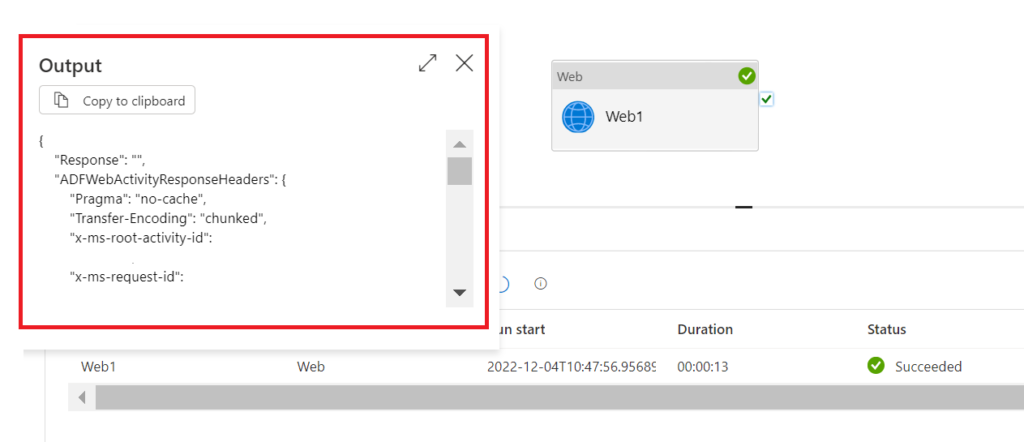
.
Another indication is the asynchronous activity should be faster than the synchronous-like one. This is actually also the case here, although with such a small semantic model, the difference is not very significant. Long story short, it still is an asynchronous call, but data factory does some smart stuff that made me think it had been synchronous. I elaborate more on this issue in the appendix. If you just want to change the API call to use the “more asynchronous behaviour”, tick the box Disable async pattern in the Advanced setting:
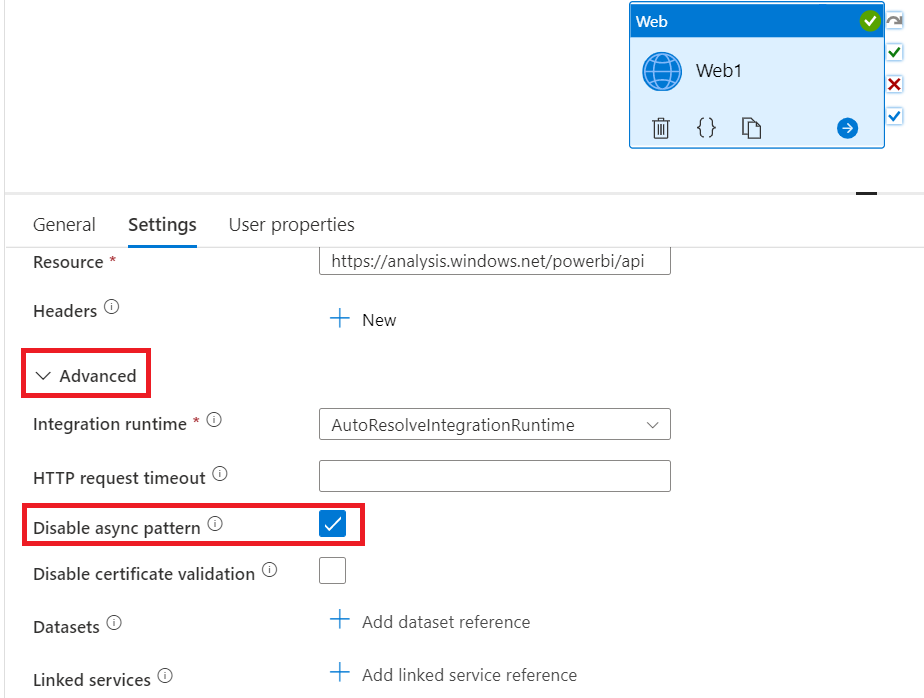
.
end.
With the enhanced API and the partitioning mirroring strategy described in the previous blog posts, we are able to tremendously slim down the ETL process. For instance, if you know which table partition in the source has been affected by the last run, you could use this information together with a meta driven approach to parse out a JSON body that refreshes only the relevant parts of the data model. If you do so, there could be the pitfall of trying to refresh the same model multiple times simultaneously. Here, it could be worth to first check whether there is an ongoing refresh run and wait for its completion before triggering a new one.
Finally, did you know that you can use Azure Data Factory not only to trigger refreshes, but also to query data directly from the semantic model. This blog post, provides a walk-through on how to do this and shows even how to copy the data from a Power BI semantic model to somewhere else.
.
appendix.
At first, I did not even realise that the call was not as I expected (that is asynchronous), since I used the almost identical web activity configuration as when refreshing a semantic model as a whole. The only difference in the settings is to use an empty body:
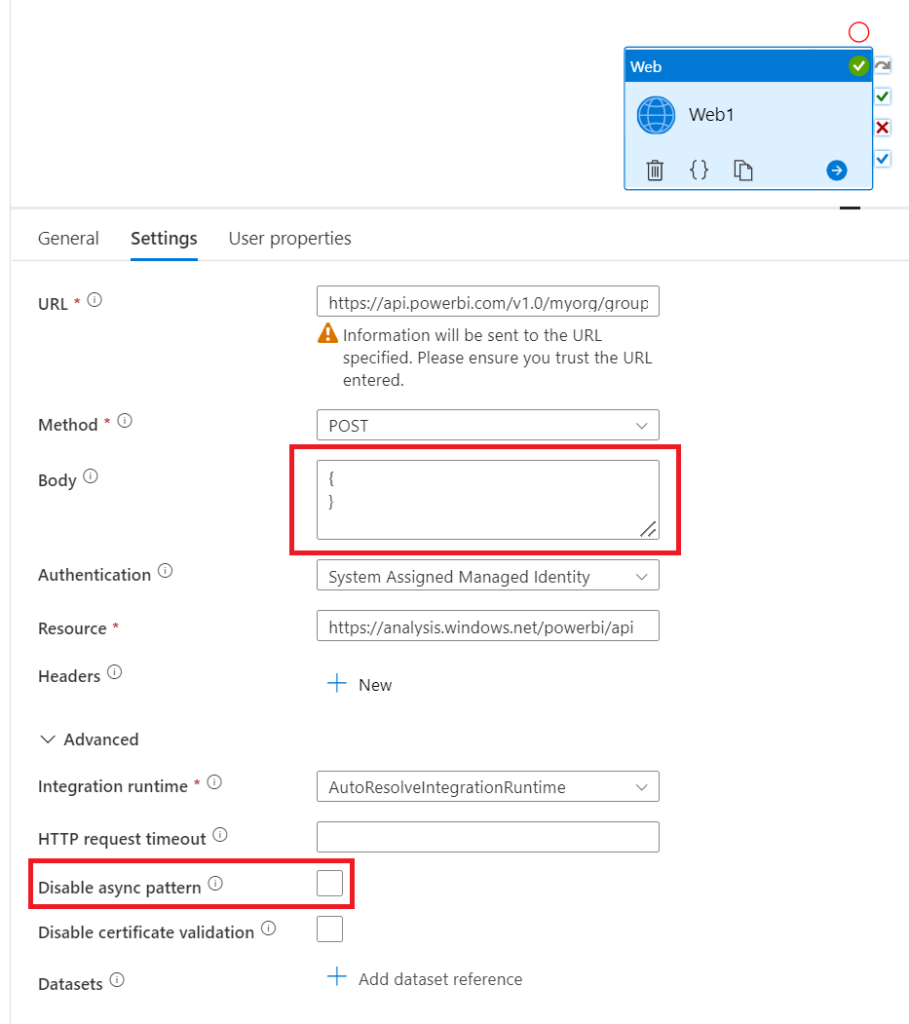
.
And with that configuration (note, the async pattern is unticked), we actually receive a response that indicates an asynchronous refresh:
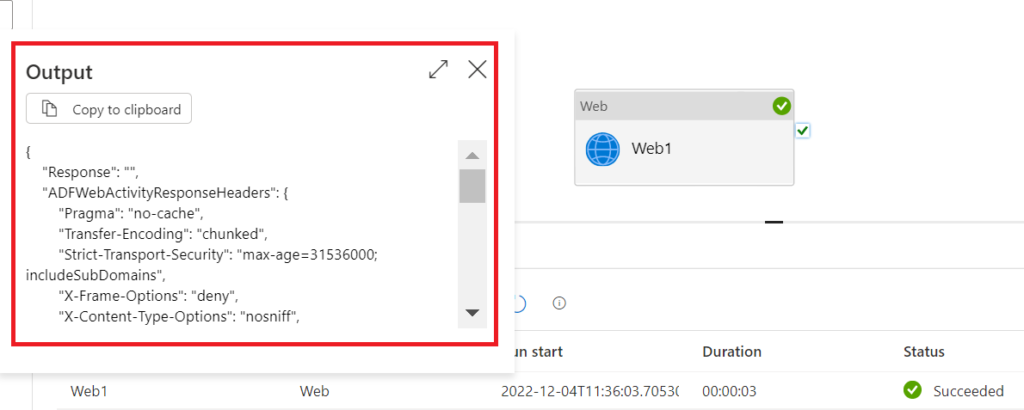
.
This is why I had the assumption to also fire an asynchronous call after I added other parts to the body (tables and partitions to refresh). However, when I tried to check on the status of that specific refresh (GetRefreshHistory API) I had to find out the pipeline failed:
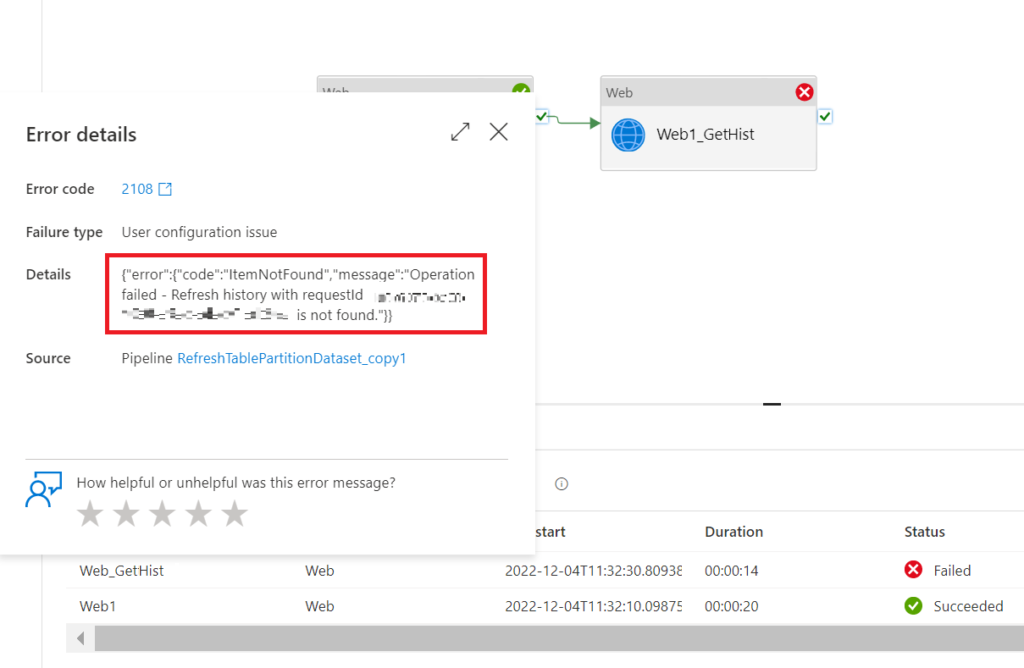
.
Here the settings for that GetRefreshHistory call:
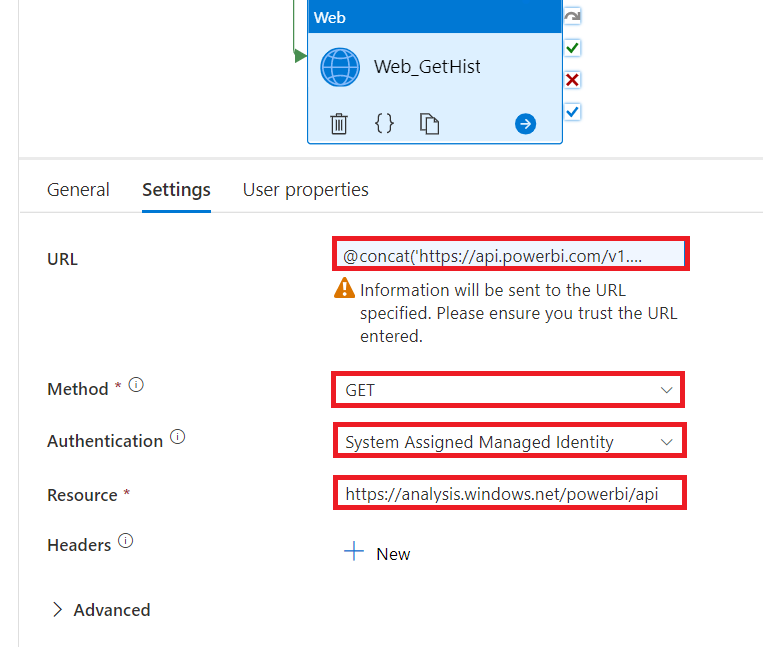
.
The URL follows this pattern:
@concat ('https://api.powerbi.com/v1.0/myorg/groups/[workspaceID]/datasets/[datasetID]/refreshes', activity('Web1').output.ADFWebActivityResponseHeaders.RequestId)
Both the workspaceID and the datasetID can be copied from the address / URL bar by clicking onto the semantic model in Power BI Service. We get the requestid directly from the output of the previous PostRefresh call.
The Method is Get
Pick System Assigned Managed Identity (Legacy: Managed Identity) as Authentication.
Lastly, set Resource to
https://analysis.windows.net/powerbi/api
.
So, here a couple of observations: The Refresh/RequestID in the output of the PostRefresh call does not work with the GetRefreshHistory (this one is obvious as it says it in the error message). Power BI Service displays a different Refresh/RequestID in the refresh history (probably the one that we should have used but had not come along from the PostRefresh output activity). And finally, when I investigated the output response more thoroughly, I saw the status completed for the tables and partitions. To be honest, at first, it was just a wild guess to check the Disable async pattern box and run the pipeline again. Yet, it worked:
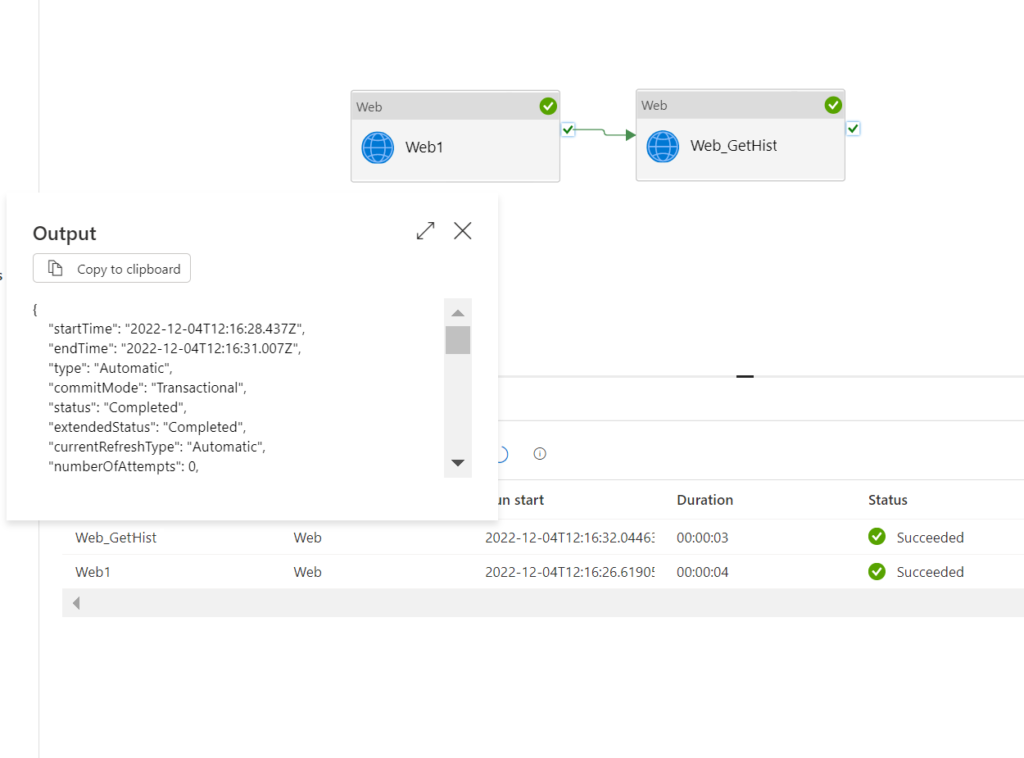
.
Note, the response of the GetRefreshHistory call looks identical to the PostRefresh call when the Disable async pattern box is unticked. It seems, when Disable async pattern is not activated, data factory first fires the PostRefresh and directly after calls for the GetRefreshHistory until it receives a proper status. In fact, this is exactly what happens: If the box is unchecked, data factory fires a get call on the content in the location field of the response header. However, data factory does this only in case it retrieves a 202 accepted response code from the original call. This would be in line with Microsoft’s documentation claiming the enhanced refresh API returns a 202. Examining the location field of the data factory response when Disable async pattern is checked, the exact same URL is shown as we use for the GetRefreshHistory API activiity.
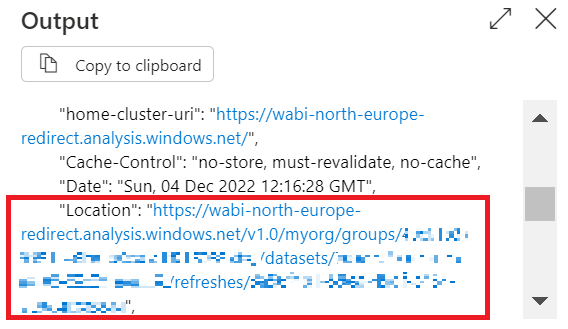
.
So, to be clear, we have not fired a synchronous API call from data factory whatsoever. It is just that data factory has this in-built-by-default-feature that gives us the perception of such a synchronous behaviour. Instead, it still is an asynchronous post call to start the refresh combined with an instant get call directly after on the URL stated in the Location field, requesting the status of that specific refresh. This is quite a cool feature since it minimises development effort. However, I like the fact we can still disable it if we want to control it ourselves.